Keep Innovating! Blog

最先端の画像生成 AIで伝言ゲームを作ったらこうなった(1)
目次
Ⅰ はじめに
はじめまして、DX推進本部の田村と申します。当社オープンストリームでは「AI人材育成プログラム」という教育プログラムがあります。このプログラムの一環として、私はText-to-Image 型の画像生成AIをテーマとして調査研究を実施しています。 特に、Stable Diffusion に興味があり、Hugging Face(https://huggingface.co/) で公開されているモデルを使用した実装などを行いました。
Stable Diffusionは、欲しい内容を言葉(テキスト)で入力すると高精細な画像として出力するという最先端の拡散モデルを使った画像生成AIです。写真のようなリアルな画像はもちろん、アート、SF・ファンタジーの世界やキャラクターのイラストなどを高品質で出力することができます。最近ネットその他で話題になっているので、機械学習に詳しくなくても知っている方、使用している方は多いのではないでしょうか?
私も初めは動作確認のつもりで、有名な「乗馬している宇宙飛行士」の画像や果物の画像を出力していましたが、だんだん面白くなって最終的には映画やゲームのシーンに出てきそうな画像をいろいろと出力することにハマってしまいました。
そうして何度も画像を生成させているうちに思いついたのが次のようなアイデアです。
実験のアイデア
- Text-to-Imageで生成した画像をImage-to-Textでイメージキャプショニングするとどのようになるか?
- さらに、そのキャプションをText-to-Imageで画像を生成するとどのようになるか?
- また、「伝言ゲーム」のようにこれを交互に実行していくと、画像やキャプショニングはどのように変化していくか?
さっそくこのアイデアをプログラミングして「伝言ゲーム」の実験をしてみましたので、本記事では、その結果についてご紹介します。
クイズ形式で紹介
通常であれば、実験の手順を最初から順番に紹介していくところですが、今回は少し趣向を変えて、まず読者のみなさんにこの伝言ゲームを体験してもらう形としてみました。つまり、AIが作った伝言ゲームの正解を読者のみなさんに考えていただくクイズという形式です。
というわけで、まず本稿では、実験の説明と最終的にAIから出力された画像をクイズの「問題」として提示し、次回の投稿で、その正解を発表いたします。
Ⅱ 実験の説明
(1) 実験方法
画像生成するテキスト(これが正解となります)を用意し、図1のように英訳後、画像生成、イメージキャプショニングを繰り返します。こうして最終的に生成された画像が伝言ゲームの「問題」の画像となります。
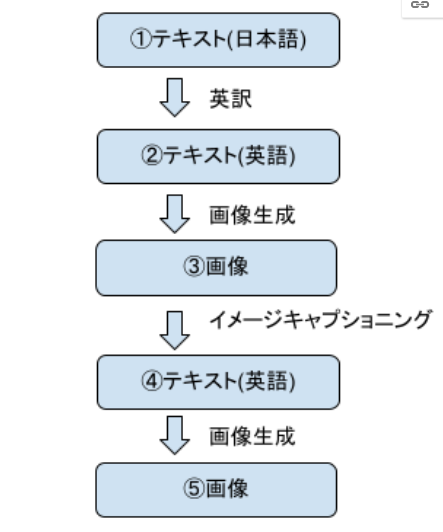
なお、用意したテキストについてですが、Stable Diffusionは表現力が豊富なため、あまりにも複雑な画像や非現実的な画像が生成されてしまうとイメージキャプショニングが難しく、またクイズ自体も高難易度になってしまいます。そのため、ある程度解答可能なシンプルなテキストを正解にしています。
(2) 実験環境
実行環境およびモデルは下記を使用しPythonのプログラムから実行しました。
- 実行環境
- Google Colaboratory ( https://colab.research.google.com )
「ノートブックの設定」で「ハードウェアアクセラレータ: GPU」を設定します。
- Google Colaboratory ( https://colab.research.google.com )
- 使用モデル
- Text-to-Image(Stable Diffusion):
- CompVis/stable-diffusion-v1-4 ( https://huggingface.co/CompVis/stable-diffusion-v1-4 )
- Image-to-Text:
- nlpconnect/vit-gpt2-image-captioning ( https://huggingface.co/nlpconnect/vit-gpt2-image-captioning )
- ※ 上記のモデルは、Hugging Faceにユーザ登録することで利用可能になります。
- Text-to-Image(Stable Diffusion):
(3) 実行コード
下記は実行したコードの抜粋です。各モデルの公式サイトにあるサンプルコードを少し変更しています。
# ライブラリをインストール
!pip install --upgrade diffusers transformers scipy > /dev/null
# Hugging Face のアクセストークンを入力
from huggingface_hub import notebook_login
notebook_login()from diffusers import StableDiffusionPipeline
from PIL import Image
import torch
from transformers import VisionEncoderDecoderModel, ViTFeatureExtractor, AutoTokenizer
from transformers import pipeline
from google.colab import drive
text = "ここに画像出力したいテキスト(英語)を入力"# Text2Image(stable-diffusion)
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to(device)sd_image = pipe(text)
image = sd_image.images[0]
# 画像を確認
image# Image2Text
image_to_text = pipeline("image-to-text", model="nlpconnect/vit-gpt2-image-captioning")text = image_to_text(image)
text = text[0]['generated_text']
# テキストの確認
textⅢ 例題
本番のクイズ出題の前に、みなさんに雰囲気をつかんでいただくために簡単な例題を出してみます。問題画像とその元になったテキストを予想してから、正解を確認してみてください。
例題の問題
下の画像から、元のテキスト(正解テキスト)を考えてみてください。

難易度: ★☆☆☆☆
例題の答え
正解は「サッカーボールを蹴っている犬」です。みなさん正解できましたか?
問題作成の手順
この問題をどのように作ったのか、その手順①〜⑤を説明します。
①テキスト(答え)
「サッカーボールを蹴っている犬」:これは出題者(私)が考えた正解テキストです。
②テキスト(英語に翻訳)
”a dog kicking a soccer ball”
このテキストを Text-to-Image モデルに入力します。
③テキストから画像を生成
以下のような画像が得られました。
さらに、この画像を Image-to-Text モデルに入力します。

④画像からテキストを生成
”a dog playing with a soccer ball” というキャプションが得られました。
さらに、このテキストを Text-to-Image モデルに入力します。
⑤画像(クイズの出題画像)
以下のような画像が得られました。これがクイズの出題画像となります。

Ⅳ 問題
では、本番のクイズを出題します。全部で5問あります。
(1) 問題1 元のテキストは何でしょう?
・難易度: ★☆☆☆☆

(2) 問題2 元のテキストは何でしょう?
・難易度: ★★☆☆☆

(3) 問題3 元のテキストは何でしょう?
・難易度: ★★★☆☆

(4) 問題4 元のテキストは何でしょう?
・難易度: ★★★★☆

(5) 問題5 元のテキストは何でしょう?
・難易度: ★★★★★

解答について
問題の解答は、次回の記事で行います。オリジナル画像が、どのようにイメージキャプショニング、画像生成されたかという過程をご確認ください。
お楽しみに!
著者プロフィール
名前: 田村行玄
株式会社オープンストリーム/DX推進本部
Web系のシステム開発やスーパーコンピュータの保守運用などを経験。現在は、クラウドやビッグデータ関連の案件に携わっている。関心がある分野は自然言語処理。
JDLA Deep Learning for ENGINEER 2020#1保有。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps