Keep Innovating! Blog

最先端の画像生成 AIで伝言ゲームを作ったらこうなった(2)解答編
目次
Ⅰ はじめに
こんにちは、DX推進本部の田村です。前回の投稿以降も Stable Diffusion を色々と試しています。今回使用したモデルの他にも、特定のゲームの世界観やアニメキャラクターなどに最適化されたモデルもあり、まだまだ楽しめそうです。
さて本稿は、前回の記事の続きです。
前回の記事では、Image-to-Text、Text-to-Imageを使用した「伝言ゲーム」型のクイズを出題しました。本稿では、その答え合わせをしていきます。
Ⅱ 伝言ゲームの仕組み(おさらい)
注:このパートは前回の記事の再掲ですので、前回理解された方は読み飛ばしてください。
前回の記事では、図1のような実験を行い、⑤で最終的に出力された画像から①のテキストを想像するというクイズを出題しました。
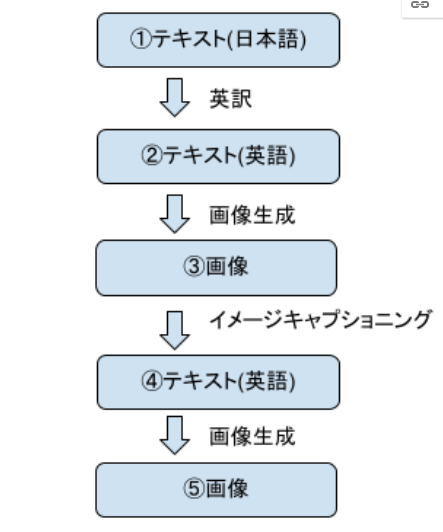
以降では、設問画像と解答をお示しするとともに、問題として用意したテキストが上記の工程を経てどのように変化していったのか、作成過程をお伝えします。
Ⅲ 解答
問題1
出題画像
(おさらい:この画像が、元はどんなテキストから生成されたのかを考えて解答する、というクイズでした)

解答
正解は、「顔が描いてあるリンゴ」でした。
問題作成過程

問題2
出題画像

解答
「お皿の上に載っている花」
問題作成過程

問題3
出題画像

解答
「背中に羽が生えた馬」
問題作成過程

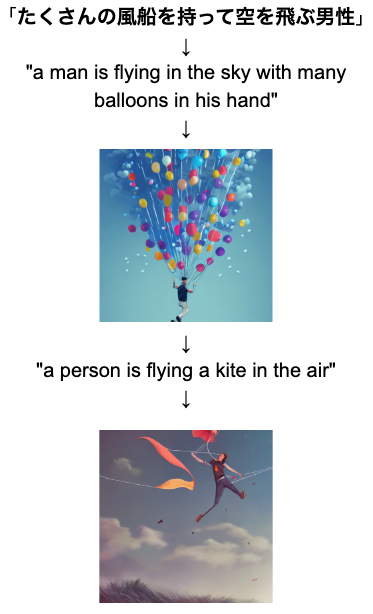
問題4
出題画像

解答
「たくさんの風船を持って空を飛ぶ男性」
問題作成過程
問題5
出題画像

解答
「乗馬する宇宙飛行士」
問題作成過程

以上で解答は終わりです。
Ⅲ おわりに
画像生成AIによる伝言ゲーム、楽しんでいただけたでしょうか?より面白いゲームにするには、テキストから画像へ変換される際の誤差をもっと大きくする等、さらに工夫を加える必要がありそうですが、今回の実験で可能性は感じることができたと思っています。
Hugging Face Hubに登録されているモデルを確認すると、stable diffusion は現在も活発に改良が行われているようです。バージョンアップされたモデルや、ファインチューニングされた多くの派生モデルが次々とアップロードされています。昨今の生成系AIや大規模言語モデルへの注目度の高さを考えると、この状況は当分の間続くのではないでしょうか。
その一方で、アメリカではStable Diffusionを含む画像生成AIの開発元に対して著作権侵害の集団訴訟が起こっています。このような問題は、人間が生み出した過去の情報から学習するという現状AIの開発方法においては避けられないものであり、AI技術を活用する際には適切な法的対応が必要です。今後の展開に注目しています。
また、これからもText-to-Image、Image-to-Textに限らずいろいろなモデルを試したりファインチューニングに挑戦していきますので、機会があればまた紹介したいと思います。
著者プロフィール
名前: 田村行玄
株式会社オープンストリーム/DX推進本部
Web系のシステム開発やスーパーコンピュータの保守運用などを経験。現在は、クラウドやビッグデータ関連の案件に携わっている。関心がある分野は自然言語処理。
JDLA Deep Learning for ENGINEER 2020#1保有。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps