Keep Innovating! Blog

”Knitfab”というリネージ管理のできる MLOps ツールをまもなくリリースします
目次
皆さんこんにちは、お久しぶりです。オープンストリーム技術創発推進室の高岡です。
いかがお過ごしでしたでしょうか。
私はというと、足掛け 2 年ほどになりますが、新しい発想の機械学習向けリネージ管理ソフトウェアを仲間とともに開発していました。その名前を “Knitfab(ニットファブ)” といいます。私は開発リーダーとして、企画、概念設計、詳細設計、実装リードを担当しています。
Knitfab は、Business Source License(BSL)のもと、ソースコードを公開する形で、来る 4/1 にリリースする予定です。

今日はそれに先立って、Knitfab のご紹介をしたく筆を執りました。どうぞお付き合いください!
リネージ管理システム?
リネージ管理システムとは、機械学習システムのなかで生まれる種々の「データ」について、それぞれがどういう経緯で作られたか?という情報(リネージ: lineage )を自動的に記録・管理するものです。
機械学習を利用した仕事をするとき、リネージ管理は非常に重要なものです。なぜならば、リネージがきちんと記録されていなければ、過去の実験やモデル作成について再現性を得ることが難しくなるからです。単に機械学習の訓練プロセスについてパラメータを記録するだけの実験管理では、残念ながら不十分です。たとえば、その訓練データが事前に前処理されていたとしたら、その前処理が何だったのか? などといった情報も必要になるからです。完全な再現性を確保するためには、実験プロセスを包括的に記録しなくてはなりません。
しかしながら、リネージ管理は手作業でやろうと思うと非常に大変で、面倒なものです。私も実際に手でやったことがありますが、正確に・もれなく記録することにはかなりの困難と苦痛が伴いました。
knitfab は、このリネージ管理が自動的にできていてほしい!という強い思いから構想したものです。
リネージ管理は、モデル開発をしていくときに必要だ
機械学習モデルの開発は、
- モデル作成: 問題の性質に応じたモデルを設計して訓練プログラムや前処理プログラム等を作成する
- 実験: モデルやプログラムに、データやハイパラを入れてみて、結果を得る
- 評価: 結果を見て、評価検討する
- 改善: 評価に基づいて、モデルやプログラムやデータやハイパーパラメータを調整する
- 以後上記の繰り返し
というサイクルをたどるものです。
このサイクルを繰り返すにあたって、「いつ、どんな条件で、何を」したのか? という記録が重要で、これなしには妥当なモデルの評価ができませんし、後々になって再現できなくなって困ることになります。
さて、この「実験 → 評価 → 改善」というワークフローはただ繰り返すだけではありません。実際にはもっと複雑な事が起きます。
- 実験の前に、データの前処理をかけたい。どういう前処理を施したデータを、どういう訓練に使ったか記録したい。
- 新しい評価スクリプトができた。既存の結果に適用して、改めて評価したい。
- 新しいモデルができた。既存のデータを入力して、結果を得たい。
- ……
このように、開発のワークフローは一本道だったり固定的だったりするものではありません。どんどん拡張・分岐・合流を繰り返しながら、より良い結果を求めて探索を繰り返すことになります。
リネージ管理とは、まさにこうした状況を対象としたものです。
リネージ管理は、モデル運用をしていくときにも、きっと必要だ
モデル開発活動が無事に進んで、機械学習モデルができた! …とします。
するとそれは現場に持ち込まれて、実際のデータを使って運用することになります。
ところが、現場のデータの傾向は時間とともに変化する場合が多いのです。たとえば、人間の行動は社会様式や流行り廃りで変化するものですし、気象などの自然現象であれば地球規模の大きなトレンドで変化していきます。するとこの機械学習モデルは、訓練時には存在しなかった新しい傾向のデータに遭遇することになるでしょう。これが『分布シフト』などとして知られる現象です。
これを踏まえると「ときどきモデルを訓練し直して新しいデータの傾向に合わせ込む」という作業(再学習や微調整・継続的学習など)が必要になってきますね。
では、どのような再訓練を施したら、どういう結果が得られたのでしょうか? それはこれまでの結果と比べて良くなったのでしょうか? その過去の結果って、どういう条件で得られたものなんでしたっけ?......再訓練を管理しようとすればこのような確認作業が必然的に生まれてきます。この確認のために必要な情報がリネージなのです。
機械学習ワークフローは煩雑だ! --- Knitfab を使おう
ここまでの説明で、リネージ管理の重要性についてご理解いただけたと思います。もう一つの問題は、ワークフローの管理です。
リネージが生じる元となっている一連の作業は、しばしば何度も繰り返すことになります。とすればこの作業手順=ワークフローも自動化されてほしいところです。例えば、運用中に適切なタイミングで自動的に性能指標が出てくる仕組みがあれば、機械学習エンジニアはそれをチェック評価するだけで済みますよね。
前節までに説明したように、開発するにも運用するにも、機械学習のワークフローはどうしても複雑なものになりがちです。手作業でこの複雑なワークフローを実行するのは大変ですし、その過程のリネージを逐一記録していくのも神経を使う作業となります。なんとかしてこうした負担を軽減できないか?というのがMLOpsにおける主要な課題の一つです。
この課題には既に多くの人たちが取り組んでおり、いろいろな解決策が提案されています。典型的な解決策は、リネージ記録(一般的には実験記録と呼ぶことが多いかも知れません)の機能を実現するためのライブラリやフレームワークを作ったり、そのためのクラウドサービスを提供したり、といったものです。これらは、もちろん有益な機能を提供してくれますし、問題解決につながる部分も多くあります。
しかし、MLOps的観点ーー研究開発から運用フィードバックまでを包括的に扱いたいーーにおいて満足でき、かつ自由に柔軟にリネージ管理したいという我々の望みを完全にかなえてくれるものはまだ少ない、ように思われます。
たとえば、そうしたフレームワークでは、自分の機械学習用プログラムの形をそのフレームワーク固有の書き方に合わせないといけないという制約があったりします。またフレームワークが使えるプログラミング言語の種類が限定されている場合もあります。クラウドサービス型のものは、情報漏洩のリスクやサービスの突然の終了(提供元の倒産や戦略変更に起因)が起こらないか?といった懸念が、長期的に使うべき MLOps基盤にとって足かせになります。
実験者は実験そのものにもっと集中してよいはずです。
実験の形はもっと自由であってよいはずです。
情報漏洩の不安なく、自前の環境で自由にアイデアを試したいはずです。
また、運用者も機械学習の問題だけに時間を取られるのは嫌でしょう。
これが私たちが Knitfab を構想した出発点にある問題意識です。
knitfab はこれらの問題を、次のようなアプローチで解決しています。
- リネージに関わるタスクは、システムが自動的に実行する:
- Knitfab は、ユーザのタスク定義とユーザが登録したデータを見比べて、まだ実行していない実験(=タスクと入力データの組み合わせ)を見つけ出すと、自動的にそのタスクを実行します。
- タスク実行の記録は全部残す:
- そうして得たタスクの出力は、リネージとして記録します。
- 過去のタスクの出力を、他のタスクに再利用する:
- Knitfab は、データがユーザによって登録されたのか、他の実験によって生成されたのか、ということを区別しません。それがなんであれ・いつ生成されたものであれ、データでありさえすればタスクの入力に使うことができます。
- 過去の実験の出力を新しい実験に入力したなら、そのまま「過去の実験の出力を、新しい実験に入力した」という記録が残ります。
- 任意のタスクをコンテナ化して実行する:
- ユーザのタスクをユーザ定義のコンテナ化された仮想環境として実行します。
- コンテナの内容は自由です。好みのプログラミング言語やフレームワークを適用できます。
- データの入出力は、任意のディレクトリを単位として行います。
- ただの kubernetes 上のシステムにすぎない:
- Knitfab 自体は、kubernetes 上で稼働する一連のコンテナの集合として構成しています。
- ユーザのタスクも、独立したコンテナに隔離されてkubernetes 上で実行します。
- そのため、knitfab は、お手元の kubernetes クラスタで稼働させることもできますし、マネージドな kubernetes で稼働させることもできます。
これらのアプローチにより、Knitfab は、タスクの連鎖全体を自動的に実行・追跡・管理できる機能を達成しました。
knitfab の世界観
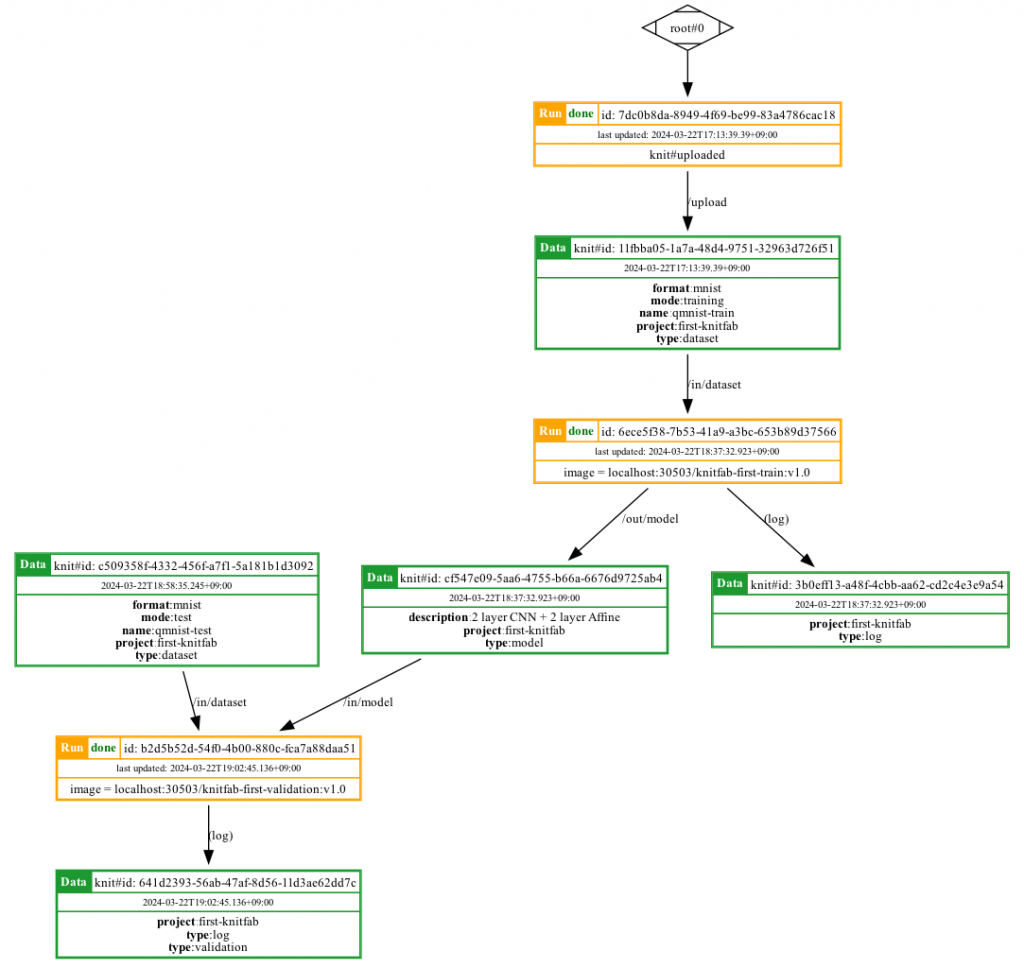
基本的な Knitfab の世界観はシンプルで、「データ」と「プラン(タスク計画)」と「ラン(タスク実行)」の 3 つのことだけしか考えません。「データが揃って実行可能になったプランは、実際にランとして実行される」ということ、これだけが Knitfab の本質的な動作です。
Knitfab は、データやプランを「タグ」というメタデータに基づいて結びつけて、”実行の準備がととのった”ランから実行します。
ユーザはCLIコマンド knit を介して、 Knitfab システム(サーバ)に対して命令を出します。Knitfab システムは、それに従ってデータとプランを登録しつつ、それらの組み合わせから実行可能な処理を探しては、見つかったら実際に Knitfab 内で処理を実行する、というのが全体の関係です。
データ
Knitfab にとってデータとは「タグがついたディレクトリ」のことです。Knitfab はディレクトリ単位でデータを取り扱います。Knitfab においては、データは一度作られると二度と内容が変わらない(イミュータブル)ものです。
データのタグは、そのデータの性質を示すものです。例えば、example プロジェクト用のデータならば、”project: example”というタグがつくでしょう。あるいは、mnist フォーマットの画像なら “format: mnist” というタグをつけてもいいですね。データにはタグを好きなだけつけることができます。
ユーザは必要に応じて、データをたくさん登録します。
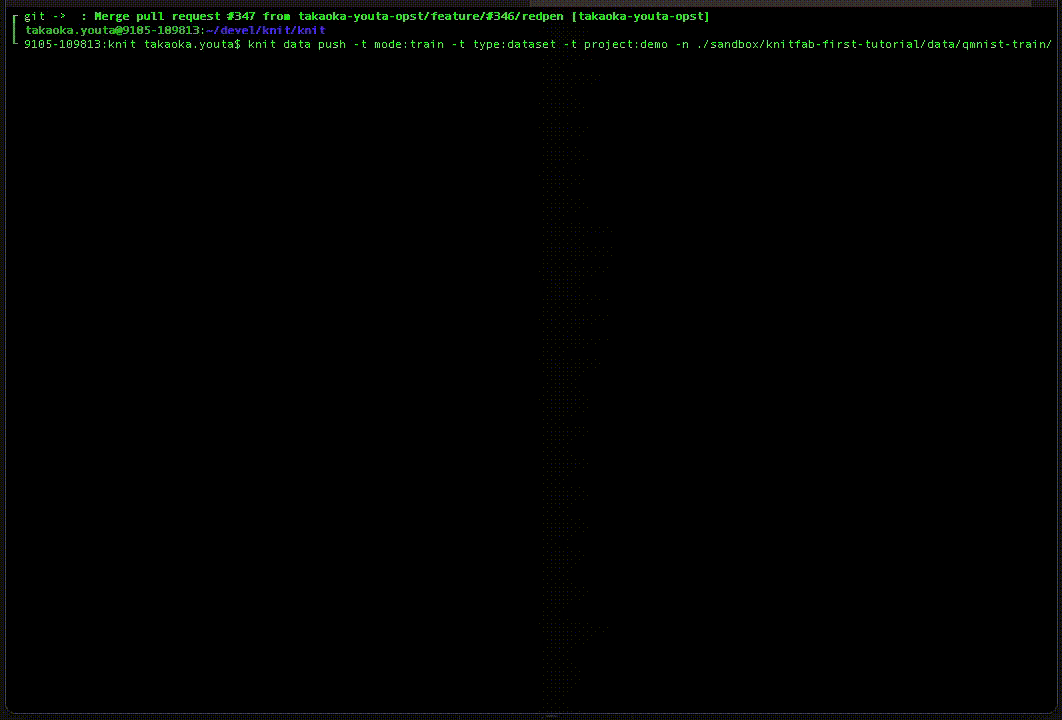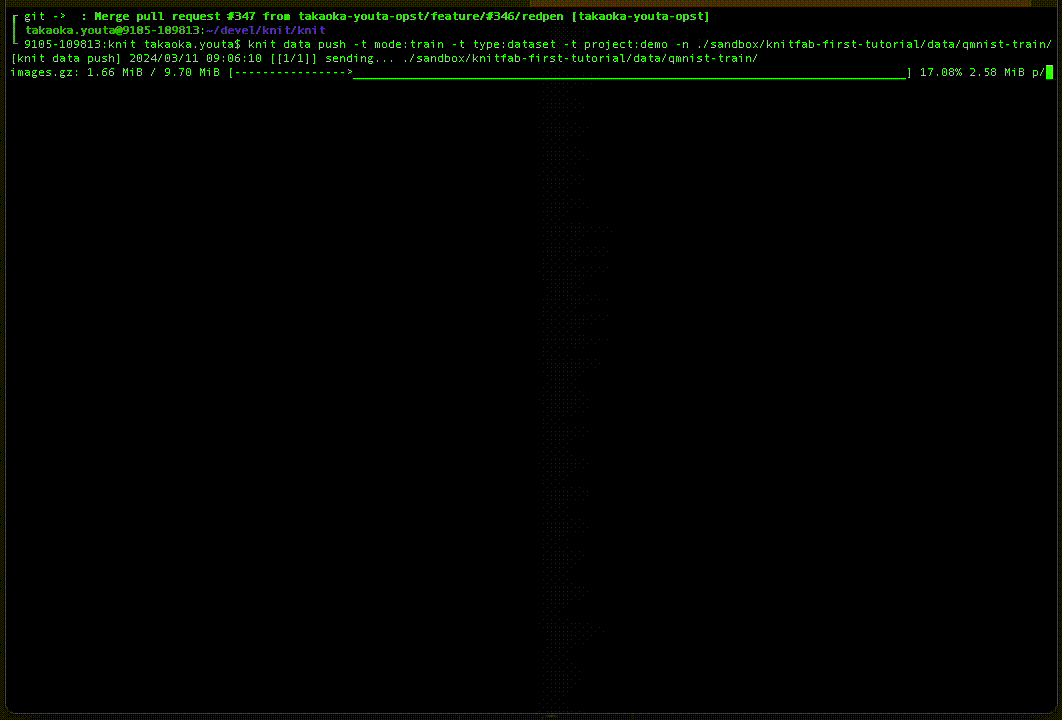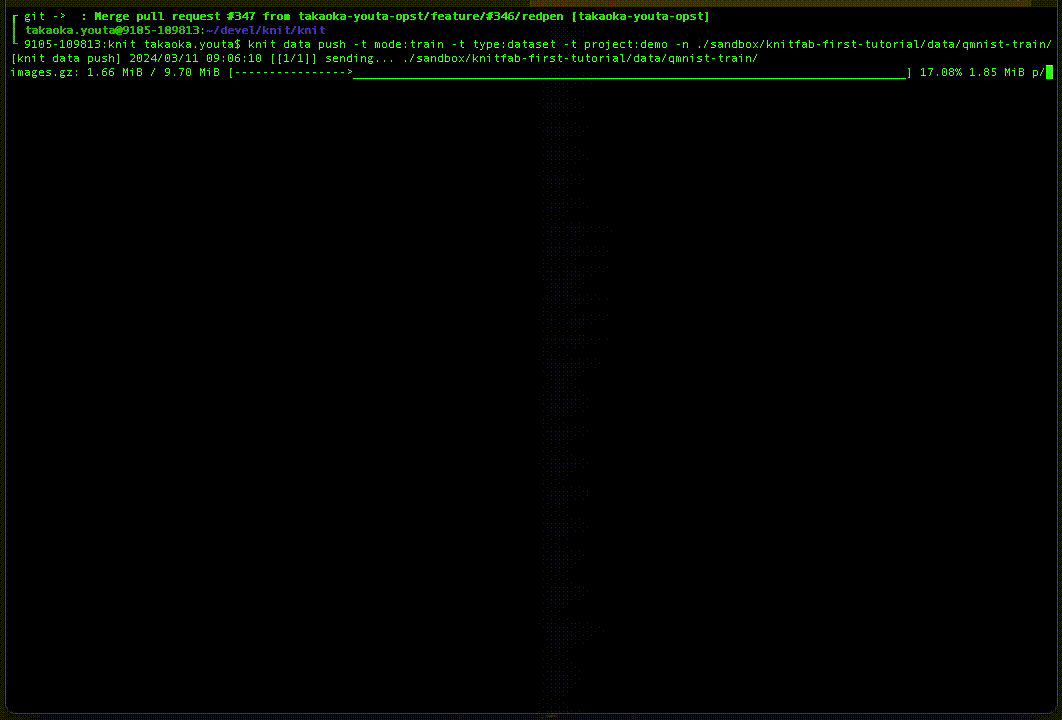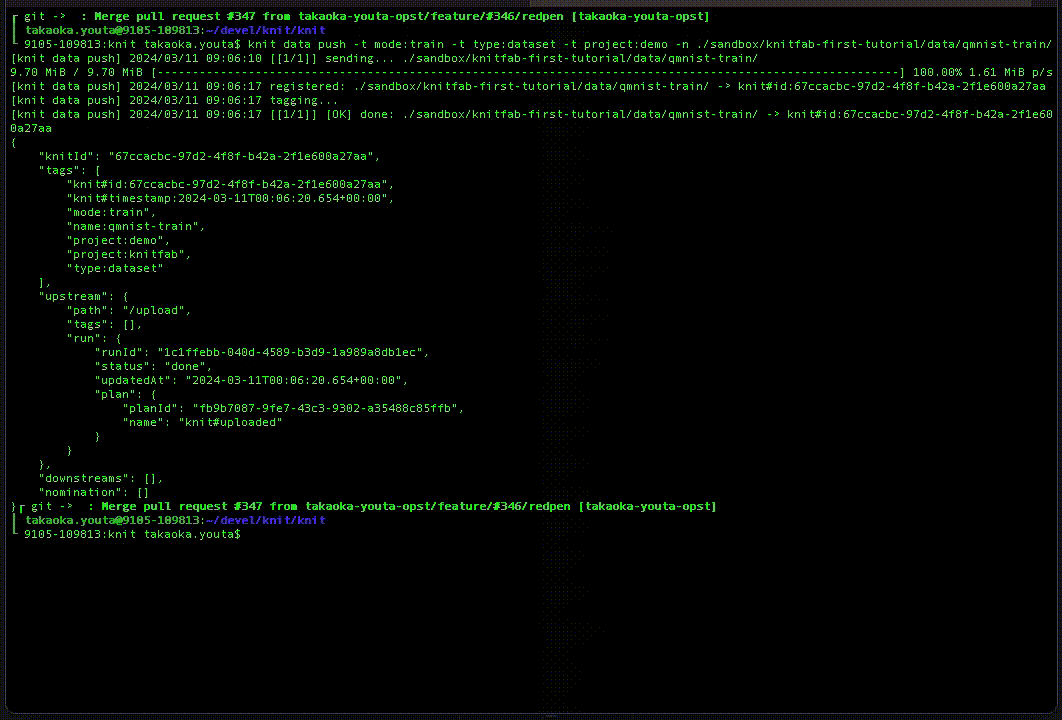
プラン
これに対してプランとは「どういうタスクに、どういうデータを入力して、どういう出力を得たいのか?」という、タスクの定義です。これも、やりたいタスクに応じてどんどん登録しましょう。
- このプランは、どういうコンテナイメージを実行するのか?
- これがタスクの内容を決めます。
- このプランは、どのディレクトリから入力を読み出すのか? またその各入力のタグはなにか?
- = それぞれの入力は、どんな性質のデータを受け取れるのか?
- このプランは、どのディレクトリに出力やログを書き出すのか? またその各出力のタグはなにか?
- = その各出力に書き出されたデータは、どんな性質のものなのか?
もうちょっと細かい設定はいろいろありますが、重要なのはこれだけです。
「このファイルパスに入力が必要だ」とプランに定義されていれば、そのプランのランを開始するときに、Knitfab が適切なデータをそのパスに配置します。出力についても、「このパスは出力だ」と定義してあれば、Knitfab はそのディレクトリの結果を自動的にリネージ付きで保存します。
プランのコンテナは、入力ディレクトリのファイルを読んで、出力ディレクトリに結果を書き出すように作成することになります。もちろん、複数の入力を読み出して(例: 「訓練データ」と「ハイパーパラメータ」)、複数の出力を書き出す(例: 「モデル」と「学習曲線」)、ということも想定されています。
タグ
さて、ここで、プランの入出力についている「タグ」が重要になってきます。
入力のタグは、その入力に渡していいデータの種類を示すものです。これは入力ごとにそれぞれ複数貼ることができます。たとえば、ある入力に ”project:example” と ”format:mnist” という 2 つのタグが貼ってあれば、(少なくとも)その両方のタグがついているデータだけが、その入力に割り当て可能だ、ということになります。Knitfab はそのプランをランとして起動するにあたって、その入力のタグが示す条件を満たすデータから、そのいずれかを入力ファイルパスに配置します。
ラン
データが増えていって、あるとき、あるプランのすべての入力に何らかのデータを割り当てることができる、とわかったとします。Knitfab は、その入力の組み合わせがまだ試されていないことを検知すると、自動的にそのプランのタスクを遂行するコンテナを立ち上げて、ランとして実行します。
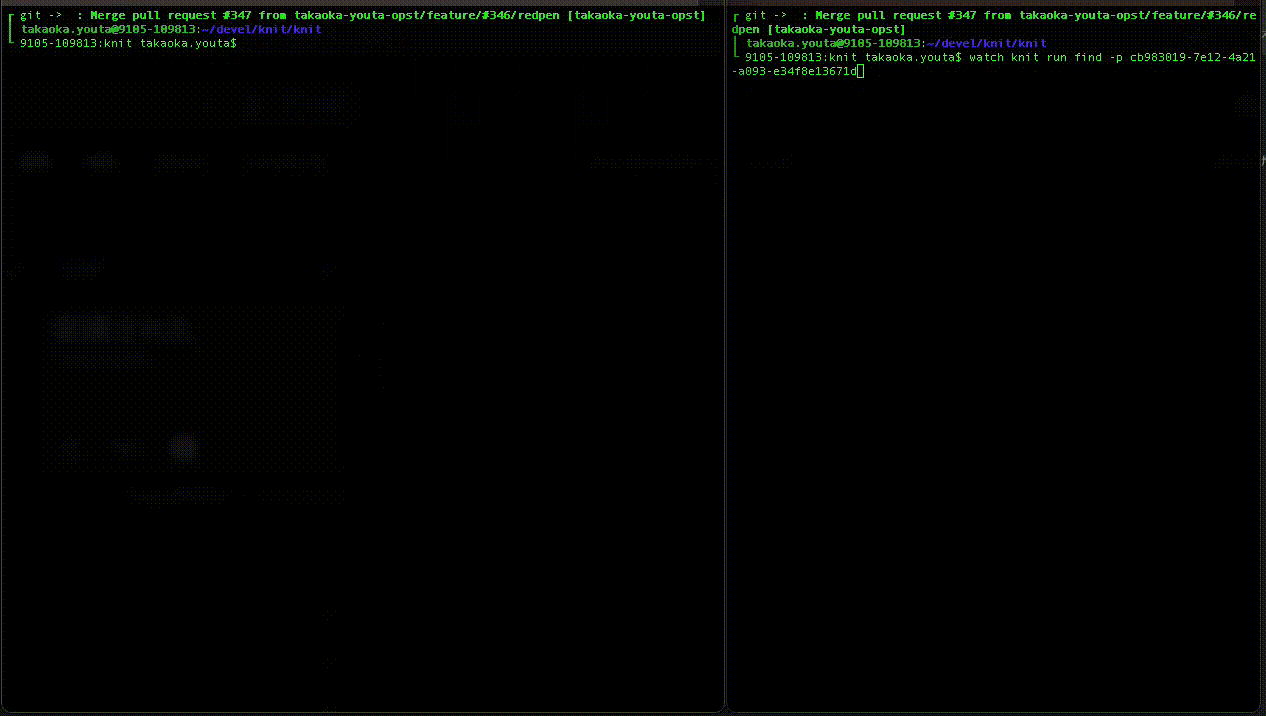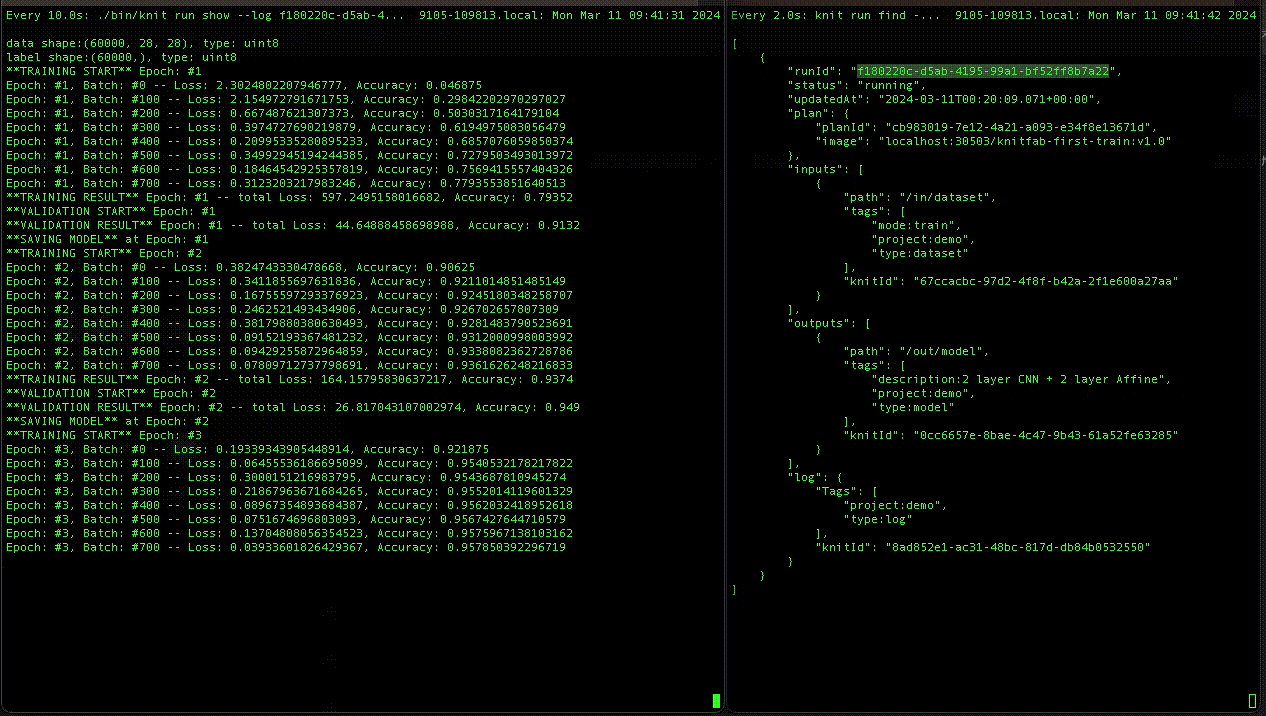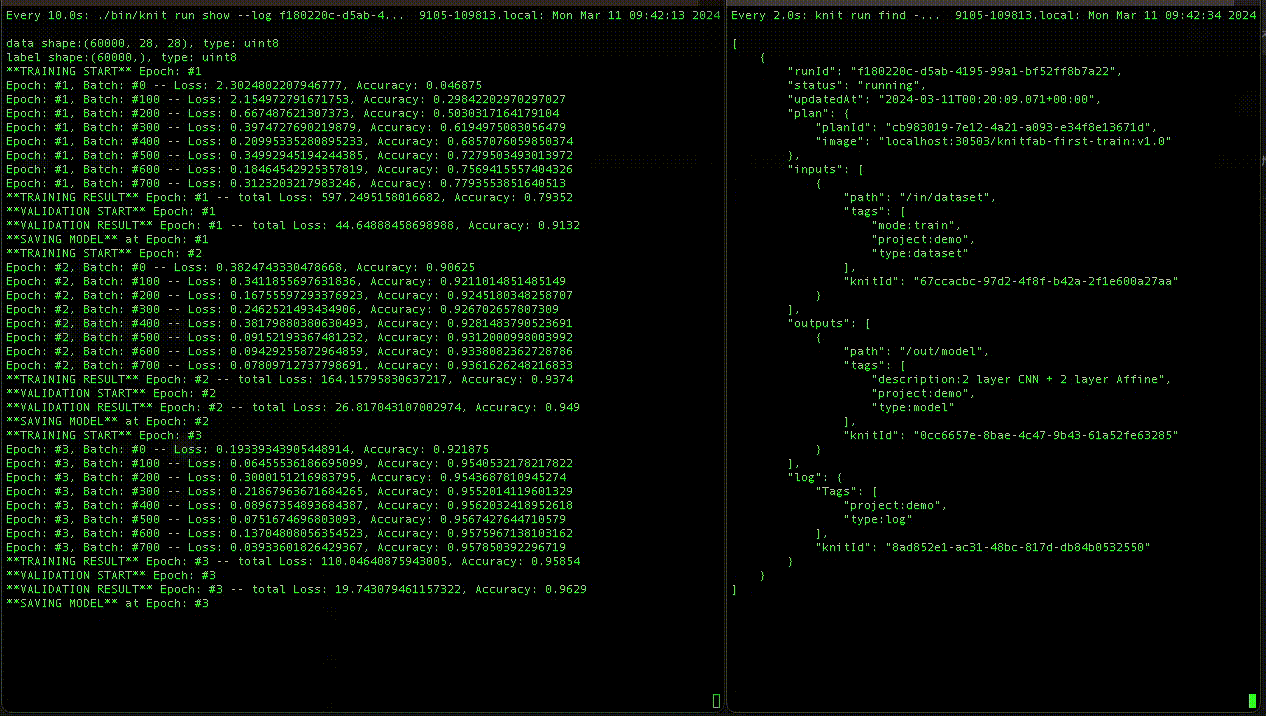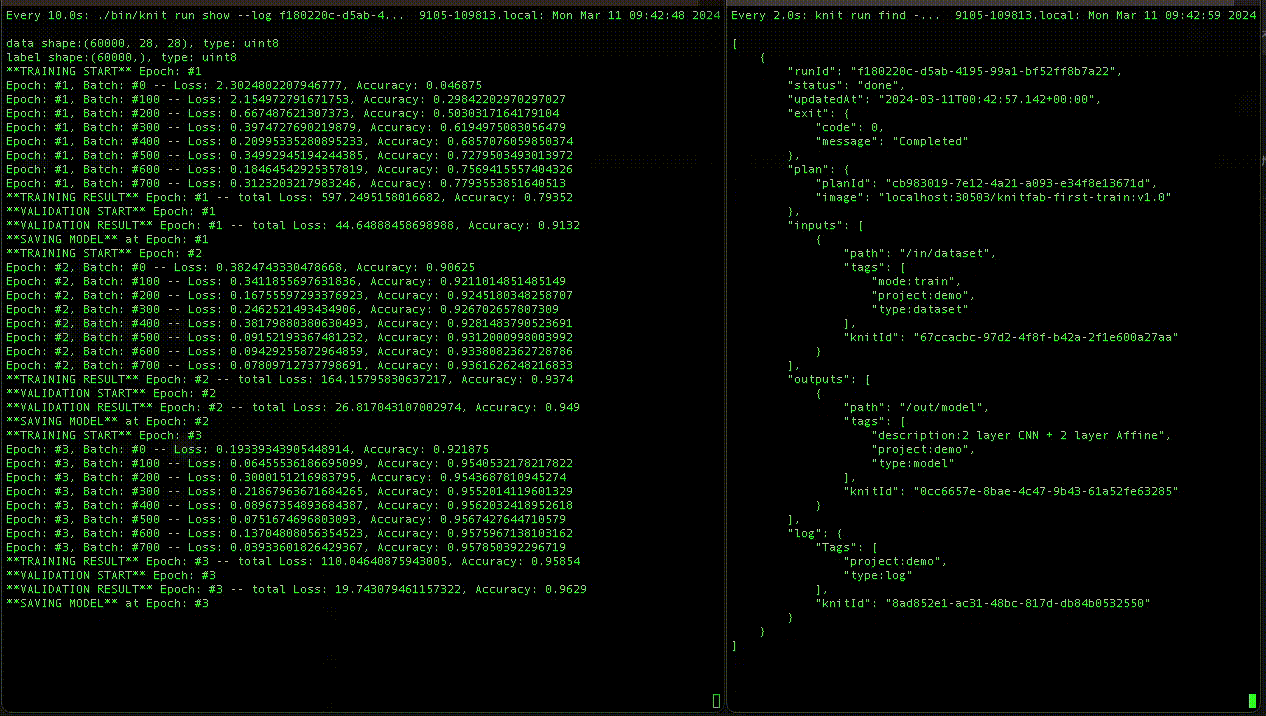
出力のタグは、その出力に書き出されたデータに自動的に設定するタグのことです。こういうわけですから、ランが出力したデータも、そのタグに従って他の処理の入力に渡されることになるでしょう。
データにはすべて「そのデータがどのランから書き出されたのか」というメタデータが記録されます。ランはすべて「どのデータを入力に起動されたか」が記録されています。ということは、この連鎖を祖先側に向かってたどると、あるデータの成立経緯をすべて把握することができる、ということです。すなわち、リネージが管理されている、ということに他なりません。
……これが、Knitfab です。
Knitfab を利用する場合には、「条件が揃ったら、このタスクをやって、記録しといて」という規則を宣言的に与えることになります。MLOps 系のフレームワークによくある「実験するから記録して」という命令的な操作とも、「定期的にこの処理を実行しておいて」というジョブ管理とも、趣が異なります。
何が「うれしい」のか?
宣言的な規則によって動作すると何がうれしいのか、ということを確認していきましょう。
実験条件の記録漏れが「ない」
Knitfab の処理は、プランに指定されているタスク(コンテナイメージ)を、入力データをディレクトリとしてアクセスできるようにしながら起動することで開始されます。
ということは、これがその処理の実験条件のほぼすべてなのです。例外は乱数シード(再現性のため、ぜひ明示化してください)とインターネットアクセス(可能ですが動的に結果が変化する接続先に注意が必要)などです。
コマンドライン引数のような揮発性の情報は、ありません。すべて入力に含まれているはずです。
ハイパーパラメータ記録用のライブラリ関数の呼び出し忘れも、ありません。書き出したものは、すべて出力やログに残ります。
前提にあるのは、「入力として指定されたデータ」と「処理を決める image」が出力を決める、という考えかたなのです。
このため、リネージだけを見れば、その処理がなにを入力に取り得たか、が確定します。
一方で、実験プログラムを作る際には、実験条件をYAMLやJSONなどの外部ファイルの形で受け取るように記述する必要はあります。また、タスクをコンテナイメージにビルドしていただく必要もあります。
ですが、きちんと管理された形で機械学習の開発/運用を行おうとすれば、そもそも実験条件にしても実験の実行方法にしても、何らかの形式を決めてファイルに保存しているものですよね? 例えば、私たちも経験がありますが、JSON 形式の設定ファイルに種々のハイパラを一括して記述できるようにしておいて、設定ファイルや訓練データセットをコマンドライン引数経由で訓練プログラムが受け取るようになっていて、訓練プログラムに引数を渡して呼び出すパターンをシェルスクリプトに書いてGitでバージョン管理する、などの方法です。
Knitfab では、この設定ファイルやデータセットが「データ」になり、シェルスクリプトがコンテナイメージになっているだけのことです。それだけで、自動的なリネージ管理がついてくるのです。
「オープンで自動的な」ワークフローが作れる
上述のように、Knitfab のワークフローは宣言的な規則が連鎖して発生するものです。逆に言えばそれは、事前にバッチ処理スクリプトのような固定的なワークフローを定めるようなものではありません。このことが Knitfab の柔軟で便利なワークフロー機能につながっています。
次のようなプランがすでにあるとしましょう。
- 「生データを入力に受け取って、前処理済みの訓練データを出力する」プラン
- 「訓練データとハイパーパラメータを入力に受け取って、訓練済みモデルパラメータを出力する」プラン
- 「訓練済みモデルパラメータを入力に受け取って、性能評価を出力する」プラン
このとき、Knitfab に「生データ」と「ハイパーパラメータ」をデータとして登録すれば、その組み合わせだけ「前処理」と「訓練」と「評価」が自動実施されます。
これは、「定期的に収集されたデータを登録すると、自動的にそれぞれ訓練を試みる」というワークフロー(データを新しく登録する場合)や、条件を変えながらモデル探索をする実験(ハイパーパラメータを新しく登録する場合)に他なりません。
新しいデータを得た、あるいは、新しい実験条件を思いついたら、それをデータとして登録するだけです。あとは Knitfab が自動的にパイプラインを実行します。
新しいプログラムで実験したくなったら、plan として Knitfab に登録しましょう。入力に指定したタグに応じて、Knitfab ができる実験を一通り実施します。
実験をまたいだ「完全なリネージ」が手に入る
Knitfab では、ある処理がデータを出力する時、「このデータは、どの処理から出力されたか」というメタデータが記録されます。また、ある処理を開始する際には「どのデータを、どの処理に入力したか」という情報も記録されます。この両者を組み合わせることで、「どのデータを、どの処理に通して、どういうデータを得たか」という記録が手に入りますね。
さらに Knitfab では、ある処理の出力を他の処理の入力としても使えるのでした。ある処理を出力されたデータが他の処理の入力に使われる際にも、やはり前述の通り「どの処理にどのデータを入力したか」が更に記録されるので、データの成立経緯の連鎖、つまりリネージの「全歴史」がすべて記録されることになります。
したがって、Knitfab が追跡するリネージは複数の実験をまたいだ「完全な」リネージです。既に述べた通りワークフローは随時拡張できるので、拡張されたらされた通りにリネージも伸びていきます。
まとめ
というわけで、私たちの新しいプロダクト Knitfab のご紹介でした。
私たちはこれが欲しい!きっと役に立つ!と思って Knitfab を作ってきました。
ぜひ皆さんにも Knitfab の「タグ」ベースのワークフローがもたらす柔軟性と、リネージが自動管理されるという安心感をお試しいただきたいと思っています。
リリース予定日は 2024年4月1日です。もうしばらくお待ち下さい!
著者プロフィール
名前: 高岡陽太
株式会社オープンストリーム/技術創発推進室
長らく Web 系のシステム開発をしてきたが、2019年頃から機械学習関連の案件に携わり始めた。
ディープラーニングモデルの開発からその API 化、フロントエンド開発まで、必要とあらば一通り手掛ける。
最近は、機械学習それ自体はもとより、機械学習開発を支える技術としての MLOps に興味を持っている。
MLOps 用基盤ツール Knitfab の開発リード。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps