Keep Innovating! Blog

Introduction of WizardCoder
目次
Hello everyone. I am Dao Duy Tung, a research engineer of AI for the Tech-Biz Co-Creation Office (技術創発推進室). Today, I would like to introduce WizardCoder[1], a State-Of-The-Art (SOTA) Open Source Code LLM model (at the time of writing this post).
I. A glance at WizardCoder
Before diving deeper into WizardCoder, I would like to make sure that we are on the same page with a short intro about 'Code LLM'. A Code LLM is the abbreviation for Large Language Model that has been trained on a massive dataset of codes of programming languages. This allows the model to learn the patterns and syntax of various programming languages, as well as the semantics of different programming concepts. Code LLMs are capable of code completion, code generation, code summarization, and code linting.
For examples of Code LLM implementation, OpenAI has unveiled Codex[2], while Google has proposed PaLM-Coder[3]. These models perform outstandingly on the popular code completion benchmarks, such as HumanEval[4] and MBPP[5], but they are closed-source. Famous open-source Code LLMs such as StarCoder[6] or CodeT5[7] still lag behind significantly.
To bridge the gap between closed-source and open-source Code LLMs, researchers of Microsoft and Hong Kong Baptist University have developed WizardCoder. Even though the base model of WizardCoder is actually StarCoder, the secret of creating a much more powerful model lies in the fine-tuning method. The central idea behind WizardCoder is "leveraging the capabilities of closed-source Code-LLMs to improve open-source Code LLMs by using fine-tuning”. At the time of writing this post, WizardCoder outperforms all other open-source Code LLMs, such as StarCoder, CodeGen[8], CodeT5+[9], on four code generation benchmarks (HumanEval, HumanEval+[10], MBPP and DS-1000[11]), and achieves SOTA performance. Remarkably, regardless of its small size (15B:15 billion parameters), it even surpasses closed-source Code LLMs such as Anthropic’s Claude[12] and Google’s Bard[13], and is about to catch up with GPT-3.5 in terms of pass rates on HumanEval and HumanEval+.
II. Brief introduction of StarCoder (precursor of WizardCoder)
First, let me give you a quick overview of StarCoder, a Code LLM that was developed by Hugging Face and other collaborators. It is trained on a massive dataset of program code from GitHub, including over 80 programming languages. The model is a decoder-only Transformer with Fill-In-the-Middle, Multi-Query-Attention, and learned absolute positional embeddings (same architecture as SantaCoder[14]). There are about 15.5 billion parameters in the model. The model was developed in 2 steps:
- Step 1: train the base model, namely StarCoderBase, on 1 trillion tokens sourced from a carefully curated dataset.
- Step 2: finetune with another 35 billion Python tokens (roughly 2 epochs) to get StarCoder
You can test StarCoder with the playground URL below:
https://huggingface.co/spaces/HuggingFaceH4/starchat-playground
Also, you can try out StarCoder in Visual Studio Code by installing the extension “HF Code Autocomplete”.
III. WizardCoder
1. Overview of fine-tuning process
StarCoder could be an amazing assistant in programming, but it can be further fine-tuned to get an even stronger model, which is WizardCoder. In order to effectively fine-tune StarCoder, a new method called Evol-Instruct was introduced to enrich the instruction datasets. From an initial set of simple instructions (these can be created by humans), another/other Code LLM(s) is/are used to generate new instructions along with new results. As illustrated in Figure 3, the Evol-Instruct pipeline mainly contains two components: Instruction Evolver and Instruction Eliminator.
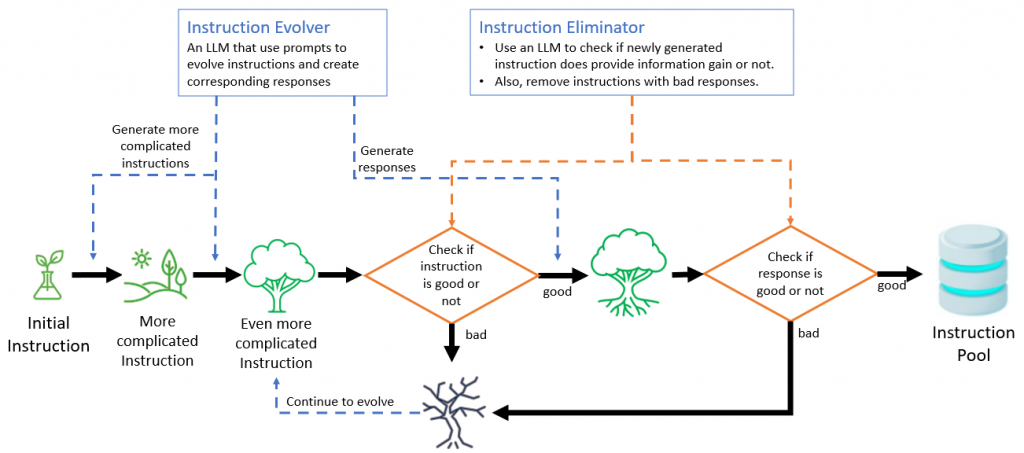
2. Instruction Evolver
Instruction Evolver is in charge of below activities:
- Generating new instructions using in-depth evolving prompt (prompt which helps increase the difficulty of the input instruction)
- Generating responses for new instructions
The below template of in-depth evolving prompt is used to generate new instructions.
Please increase the difficulty of the given programming test question a bit.
You can increase the difficulty using, but not limited to, the following methods:
{method}
{question}
{question} represents the current code instruction awaiting evolution, and {method} is the type of evolution.
There are 5 methods of evolution:
- Add new constraints and requirements to the original problem, which adds approximately 10 additional words.
- Replace a commonly used requirement in the programming task with a less common and more specific one.
- If the original problem can be solved with only a few logical steps, please add more reasoning steps.
- Provide a piece of erroneous code as a reference to increase misdirection.
- Propose higher time or space complexity requirements, but please refrain from doing so frequently.
Method 4) is for code debugging; and, method 5) is for code time-space complexity constraints
The In-Breadth Evolving process, which was used to generate a completely new instruction based on the given instruction in WizardLM’s paper[15], is removed from the pipeline because we no longer need fields other than coding.
3. Instruction Eliminator
The following situations are considered instruction evolution failures that will be removed or set back by Instruction Eliminator:
- ChatGPT determines that the evolved instruction does not provide any information gain compared to the original one
- The evolved instruction makes it difficult for the LLM to generate a response. For example, when the generated response contains “sorry” and is relatively short in length (i.e., less than 80 words), it often indicates that the LLM struggles to respond to the evolved instruction. So we can use this rule to make a judgment.
- The response generated by the LLM only contains punctuation and stop words.
- The evolved instruction clearly copies some words from the evolving prompt, such as “given prompt”, “rewritten prompt”, and “#Rewritten Prompt#”, etc.
4. Training WizardCoder (Or Fine-tuning StartCoder)
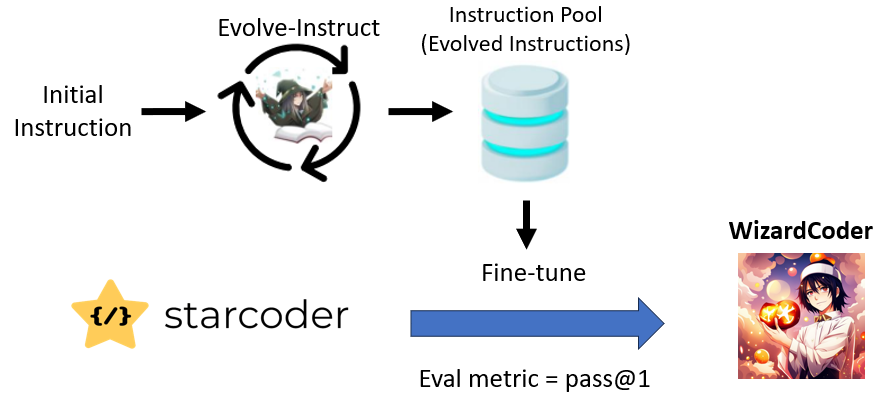
As illustrated in Figure 4, the training process contains the steps below:
- To construct the training dataset, the Evol-Instruct technique was iteratively employed on the 20K instruction-following dataset called Code Alpaca to produce evolved data. The evolved dataset consists of approximately 78k samples.
- Fine-tune StarCoder with evolved instruction data and specific configuration as follows:
- Batch size of 512, a sequence length of 2048, 200 fine-tuning steps, 30 warmup steps, a learning rate of 2e-5, a Cosine learning rate scheduler, and fp16 mixed precision
- Assess using the pass@1 metric on the HumanEval dataset.
- The metric pass@1 is one particular form of pass@k. The metric pass@k generates k code samples per problem. A problem is deemed solved if any of the samples pass the tests. The value of the metric is the fraction of solved problems.
- Once there is a decline in the pass@1 metric, the usage of Evol-Instruct is discontinued and the model with the highest pass@1 is chosen to be the ultimate model.
5. WizardCoder’s evaluation
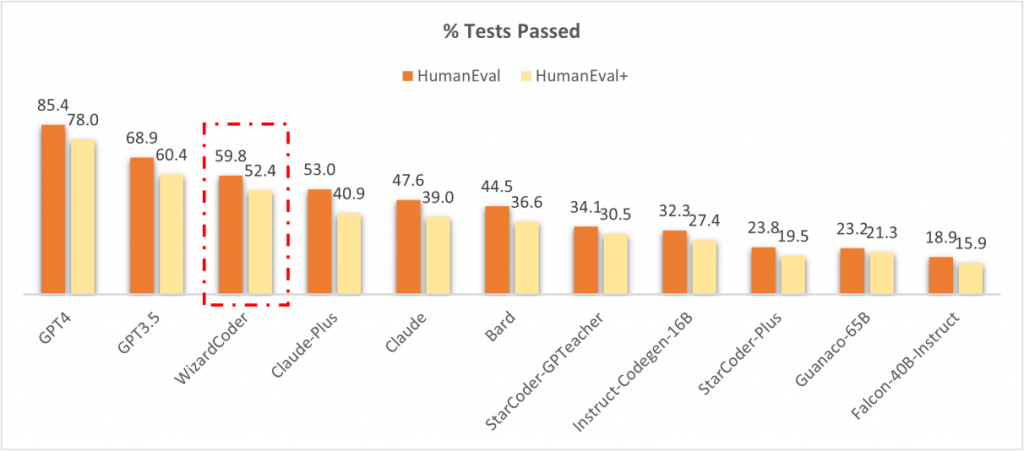
As we can see in Figure 3, in the benchmark using HumanEval and HumanEval+ dataset for evaluation, WizardCoder attains the third position in this benchmark, surpassing Claude-Plus (59.8 vs. 53.0) and Bard (59.8 vs. 44.5). Notably, the model exhibits a substantially smaller size (only 15B) compared to these models. Furthermore, WizardCoder demonstrates a remarkable superiority over other open-source LLMs that undergo instruction fine-tuning, showcasing a significant performance margin.
WizardCoder also performs better than other open-source Code LLMs on the DS-1000 dataset, which comprises 1,000 distinct data science workflows spanning seven Python libraries (Matplotlib, NumPy, Pandas, SciPy, Scikit-Learn, PyTorch, and TensorFlow). For details, please refer to the paper “WizardCoder: Empowering Code Large Language Models with Evol-Instruct”.
IV. Conclusion
We might think of WizardCoder as the result of transferring the knowledge of top closed-source Code LLMs to an open-source Code LLM. Instead of subscribing to paid services to use closed-source Code LLMs, we can have a cheaper solution yet decent performance compared to the paid solution.
On the other hand, this approach might also benefit the situation where there is a need to fine-tune Code LLM on new libraries (maybe a proprietary one).For those who want to further investigate WizardCoder, please refer to the References section. Besides the papers, there is a link to the WizardCoder GitHub project[16], where you can find the training scripts of WizardCoder[17]. There is also a link to the WizardCoder model on the Hugging Face, by using this, you can try out the model on your own.
V. References
- WizardCoder paper: https://arxiv.org/abs/2306.08568
- OpenAI’s Codex paper: https://arxiv.org/abs/2107.03374
- PaLM-Coder info: https://blog.research.google/2022/04/pathways-language-model-palm-scaling-to.html
- HumanEval dataset: https://paperswithcode.com/dataset/humaneval
- MBPP dataset: https://huggingface.co/datasets/mbpp
- StarCoder paper: https://arxiv.org/abs/2305.06161
- CodeT5 paper: https://arxiv.org/abs/2109.00859
- CodeGen paper: https://arxiv.org/abs/2203.13474
- CodeT5+ paper: https://arxiv.org/abs/2305.07922
- HumanEval+ dataset: created by researchers who wrote the following paper: https://arxiv.org/pdf/2305.01210.pdf
- DS-1000 dataset: https://github.com/HKUNLP/DS-1000
- Anthropic’s Claude page: https://www.anthropic.com/index/introducing-claude
- Google’s Bard introduction paper: https://ai.google/static/documents/google-about-bard.pdf
- SantaCoder paper: https://arxiv.org/abs/2301.03988
- WizardLM paper: https://arxiv.org/abs/2304.12244
- WizardCoder GitHub project: https://GitHub.com/nlpxucan/WizardLM/tree/main/WizardCoder
- WizardCoder model: https://huggingface.co/WizardLM/WizardCoder-15B-V1.0
- StarCoder playground: https://huggingface.co/spaces/HuggingFaceH4/starchat-playground
- Code Llama’s introduction: https://ai.meta.com/blog/code-llama-large-language-model-coding/
VI. UPDATES
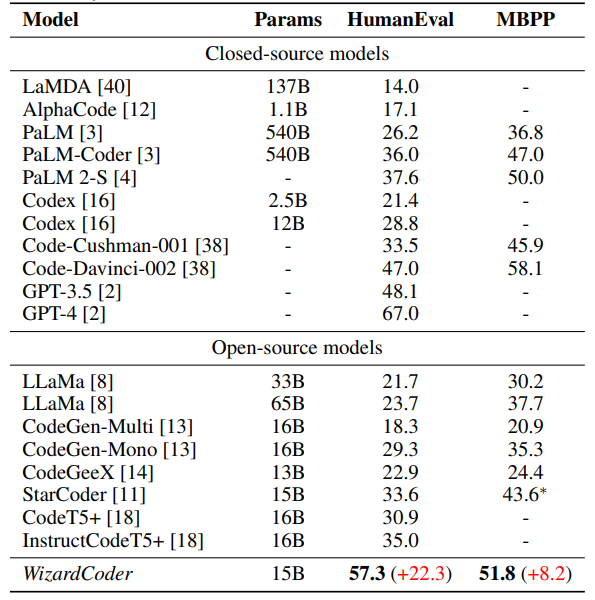
On August 24th, Meta released the open-source Code Llama-34B which can perform better than GPT-3.5 (as of 2023/03/15) on the HumanEval dataset (Code Llama’s pass@1 is 48.8% while that of GPT-3.5 is 48.1%). Even though Code Llama’s number of parameters is more than twice that of WizardCoder (34B to 15B) , the performance on the HumanEval dataset is still not on par with WizardCoder (57.3%).
OpenAI also keeps updating their model, and in fact, the latest models have improved their strength when tested against the HumanEval dataset: 82.0% for GPT-4 and 72.5% for GPT-3.5 (verified by the WizardLM scientist team). In order to catch up with OpenAI, the WizardLM scientist team has just released a newer version of WizardCoder, which is WizardCoder-Python-34B-V1.0. This model was based on Code Llama-34B[19] and then fine-tuned using the dataset generated by the Evol-Instruct method (as mentioned above). This new model has beaten all previous models on the HumanEval benchmark with 73.2% pass@1. You can find the information about this new model here:
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps