Keep Innovating! Blog

[Knitfab 技術ハイライト] 機械学習タスクを過不足なく自動実行する技術 -- #1 自動ワークフローのオーバービュー
はじめに
みなさんこんにちは。株式会社オープンストリーム・技術創発推進室、Knitfabチーフプログラマの高岡です。Knitfab をリリースしてから、早いものでもう1ヶ月。私達は日々、 Knitfab の改善を進めているところです。その改善バージョンも近いうちにお届けできると思います。お楽しみに!
さて、Knitfab の主要機能のひとつである「自動ワークフロー」について、その詳細に迫る 3 回シリーズの連載記事を書くことにしました。Knitfabががどうやって機械学習タスクを進めるのか、その技術的な舞台裏を皆さんにご紹介していきたいと思っています。この記事はその 1 本目です。
- #1 自動ワークフローのオーバービュー (今回)
- #2 Nomination: “使える Data” はどれなんだ
- #3 Projection: “足りない Run” を見つけ出す
自動ワークフロー機能は、Knitfab の設計の中心的なテーマです。そして、「自動ワークフロー機能が正しく動けば、Knitfab は正しく動く」と言えるほどに重要な機能です。というのも、Knitfab のもうひとつの主要機能である自動リネージ管理機能は、設計上は自動ワークフロー機能の動作記録をとっているものに過ぎないからです。
自動ワークフロー機能が実現したいことを一言で言えば「実行できる機械学習タスクを漏れなく・重複なく、全部実行する」というシンプルなものですが、これを実現するには色々工夫が必要で、ちょっと他でやったことのない手法を採用することになりました。私たちが開発で一番苦労した部分ですし、技術的にもちょっとおもしろい部分だと思っています。
この連載を通じて、この Knitfab 技術のおもしろさを感じていただければ幸いです。
機械学習タスク: Run
Knitfab では「機械学習タスクを実行した」あるいは「実行しつつある」という記録を Run という概念として取り扱っています。Run が生成され、コンテナとして実行されることで、機械学習タスクが実行されるのです。
下図は Run が生成する流れのイメージを図示したものです。
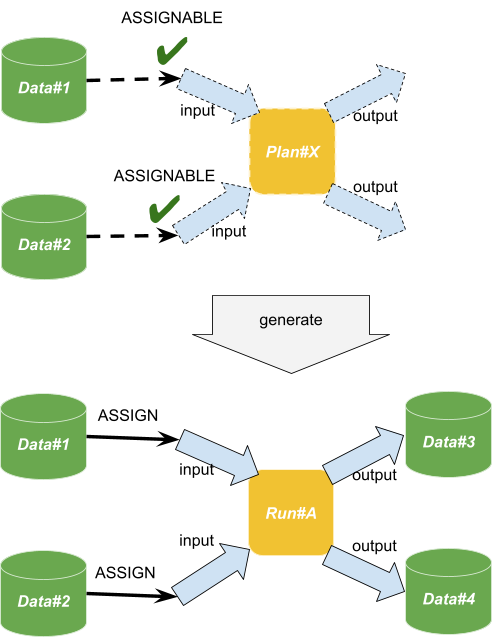
Knitfab では、Run は、その雛形にあたる Plan から生成される、という仕様になっています。上図は、ある Plan(Plan#X)から、Run (Run#A) が生成される様子を示したものです。
Knitfab は、ある Plan のすべての入力に、アサインできる条件を満たした Data があることを検出すると、入力ごとに具体的な Data をひとつづつアサインして、 Run を生成します。上図では、Plan#X に入力が 2 つ、出力が 2 つ定義されていて、2 つの入力はそれぞれ Data#1 と Data#2 がアサイン可能だ、ということになっています。Plan#X のすべての入力にアサイン可能な Data があるので、Knitfab は Plan#X に基づいて Run#A を生成しました。
Run が生成されると、Knitfab はそれをコンテナとして実行します。その際には、入力に対応するディレクトリに Data の内容がマウントされます。また、出力側にも、新しい空の Data を作ってマウントします。
Run は Knitfab によって自動的に生成されて、自動的に実行されるものです。このためには、Knitfab 自身が「生成可能な Run」とはどういうものなのかを判断できなくてはいけません。また、生成可能だといっても、すでに実行したものと同じ Run を繰り返し生成してもいけません。
この機能を実装するうえで問題になったのは
- 「Data を入力にアサインできること」をどう検出したらいいか
- 生成できる Run を漏れなく・重複なくすべて生成するにはどうすればいいか
の 2 点でした。
Knitfab では、前者は Tag によって、後者は Nomination と Projection という 2 段構えの仕組みで実現しています。
今回は Tag について説明し、さらに全体の見通しを示します。次回以降で Nomination と Projection についてそれぞれ深堀りしてゆきます。
Tag: Knitfab を編み上げるもの
入力に対してアサイン可能な Data を決定する上で、Knitfab は Data や Plan の入力につけられた Tag という、キーとバリューの組からなるメタデータを参照します。
ユーザは Data に、自由に Tag をつけることができます。Data に Tag をつけることで、その性質をあらわしたり、あるいは Data についてのメモを書きつけたりできます。
また、Knitfab の Plan の入力の「Dataをアサインしてよい条件」も Tag の集合として表現します。「入力についている Tag が、すべて Data にもある」なら、その Data は入力に対してアサイン可能です。
次図の例をご覧ください。
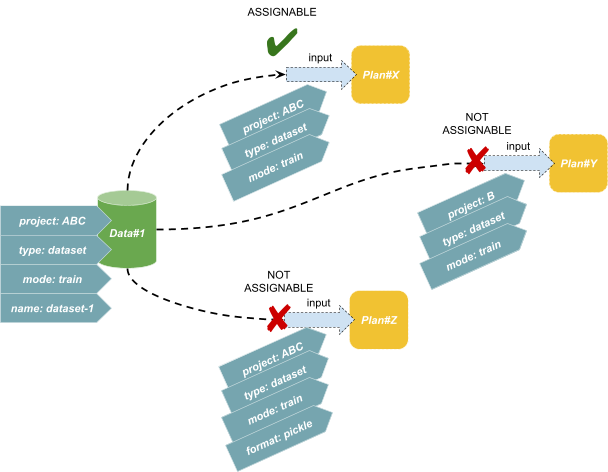
ある Data (Data#1) があって、これに4つの Tag (“project: ABC”, “type: dataset”, “mode: train”, “name: dataset-1”)がついているとします。
Plan#X の入力には、この Data#1 をアサインできます。なぜならば、Data#1 は Plan#X の入力に指定されている Tag をすべて持っているからです。(入力から見ると余計な Tag が Data#a についているように見えますが、これは問題になりません)。一方で、Plan#Y や Plan#Z の入力には、Data#1 をアサインできません。なぜならば、Data#1 には “project: B” や “format: pickle” がないので、入力に対して Data#1 の Tag が不足しているからです。
このように「Data が入力の Tag をすべて持っていること」が「その Data が 入力の要求をすべて満たしている」ということ、すなわちアサイン可能であることを意味しています。
Nomination & Projection: 過不足なく Run を生成するために
Knitfab は、ある Plan のすべての入力にアサイン可能な Data があることを検出すると、最終的には入力と Data のすべての組み合わせから Run を生成します。
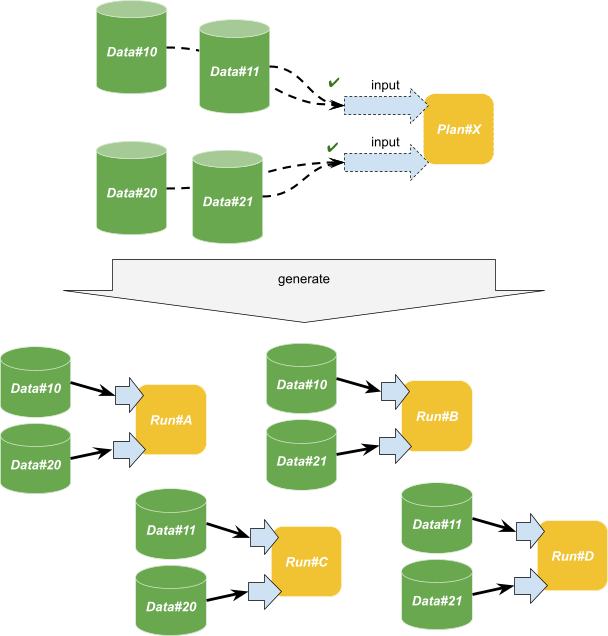
たとえば、上図のように、ある Plan (Plan#X) の 2 つの入力に対して、それぞれ 2つの Data がアサインできるなら、Knitfab は Plan#X について 2 × 2 で 4 通りの入力パターンの Run を作り出す、というわけです。
これを、漏れなく・重複なく実行しなければなりません。また、無駄な計算をできるだけ減らしたいです。そこで、我々はこのアルゴリズムを、2 つのステップに分割するように設計しました。
- Nomination: Plan の入力にアサイン可能な Data の一覧を更新・管理する。
- Projection: Nomination と既存の Run に基づいて、未実施の Run を検出する
Knitfab が Nomination ステップを実行するのは、アサイン候補の一覧を更新したいときですから、Data につけられている Tag が更新された時・Plan が新しく登録されたときです。Nomination によって、入力とそれにアサイン可能になった Data の組(アサイン候補)が一覧に登録され、逆にアサイン不可能になったアサイン候補は一覧から取り除かれます。
そしてこれとは別に、Knitfab は定期的に Projection ステップを実行します。Projection では、 Nomination によって管理されているアサイン候補一覧を参照しながら、Plan の各入力に実際にアサインする Data を組み合わせて Run を生成します。また、既存の Run と同じものが生成されないように検証します。
こう分割することで、 いくつかのメリットがあります。
まず、ユーザに操作結果を速やかに返せるようになります。アサイン候補一覧が更新されるのは既に述べた通り Data の Tag を更新したときか Plan を登録したときですが、いずれもユーザの能動的な操作に由来します。Nomination までで一度処理を打ち切ることができるなら、Projection 分の時間を待たせることなく、ユーザに操作結果を返すことができます。
次に、Run を生成しようとするたびにアサイン可能性の判定をしなくてよくなります。アサイン可能性の判定は、本質的に Data × 入力 の数だけ Tag 集合の比較を行う必要があります。一方で、一度アサイン候補一覧を得たら、Data や Plan が変化するまではアサイン候補一覧にも変化はありません。Nomination によってアサイン候補一覧を管理することで、アサイン候補の新規追加分と削除分だけを差分更新すれば済むようになりました。また一方の Projection は、 Nomination から分割されたことで、Nomination によって得たアサイン候補一覧を繰り返し再利用可能になりました。Projection は定期的にアサイン候補一覧をチェックして、変化があったときだけ実行すればよいのです。
最後に、 Projection の要否が簡単に判断できるようになったので、Projection を小刻みに実行できるようになりました。Run を生成する処理の間はアサイン候補一覧に変化があっては困ります。特に Data が削除されると、アサインしようとした Data が突然消滅する可能性があるので非常に困ります。したがって、Projection 中は Nomination に影響が出るような操作、すなわち Data の Tag を変更する操作や Plan を登録する操作をブロックしなければならないのです。しかし、Projection を小刻みに分割できるなら、この問題を緩和できます。分割された Projection の隙間にユーザ操作を割り込ませることができるからです。さらに、一度に要求するメモリや時間も、部分的になるので抑えることができます。
ここまでのまとめ
この記事では、次の内容を扱いました。
- Knitfab における Tag と Run 生成の関係を説明しました。
- また、Nomination と Projection という 2 つのステップが存在していることを説明しました。
- Nomination から Projection を切り離すことで、大きな問題を少しづつ処理しています。
次回は、Nomination について、そのアルゴリズムと実装上の工夫を説明します。お楽しみに!
著者プロフィール
名前: 高岡陽太
株式会社オープンストリーム/技術創発推進室
長らく Web 系のシステム開発をしてきたが、2019年頃から機械学習関連の案件に携わり始めた。
ディープラーニングモデルの開発からその API 化、フロントエンド開発まで、必要とあらば一通り手掛ける。
最近は、機械学習それ自体はもとより、機械学習開発を支える技術としての MLOps に興味を持っている。
MLOps 用基盤ツール Knitfab の開発リード。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps