Keep Innovating! Blog

世の人もすなる Airflow というものを、してみんとてするなり
目次
みなさんこんにちは。技術創発推進室の高岡です。
気の早い桜は咲き始めたようですが、そろそろ年度末、みなさまいかがお過ごしでしょうか。
このところの私は、これまでの AI 関連の開発を振り返って、実験管理、結構面倒くさかったな、という反省をしているところです。機械学習系の案件に関わっている皆さんには、ご同意いただけるんじゃないでしょうか。
■実験管理は必須。でも面倒!
機械学習モデル開発のワークフローでは、次のような作業がよく発生します。
- あるデータと設定で、機械学習モデルを訓練して、パラメータを得る
- 訓練済みの機械学習モデルの性能を調べて、記録する
- モデル同士の性能を比較する
こうした「条件設定と訓練、性能測定、比較」のサイクルを「実験」と呼び、実験を繰り返しながら、より良いモデルを模索するわけです。経験者の皆さんにはおなじみですね。
このとき「このモデルはどういう条件の下で得られたか」「それをどう評価したらどうなったか」という記録を残すことはマストです。モデルの改良案を練るのも、新規モデルはこれまでのものより優秀なのか判断するのも、記録あってのことだから、ですね。
さて、面倒なのは、まさにこの「記録を残す」ことです。面倒くさい手順があれば、人間はミスをするものです。ワークフローを横展開しようにも、人に伝えるのだって大変です。不必要に面倒な手順にはいいことがありません。「面倒は悪」と言ってしまってよいでしょう。
まあ、ちゃんとやらない奴が悪い、という話にしちゃってもいいんですが、それはちょっと面白くありません。「いい仕組みを入れることで、問題を解消したい」というのは、システムエンジニアたるこの私にとって、自然な願いです。
私にもMLOps なるものに手を付ける頃合いがやってきたのだ、ということでしょう。そこで、噂のワークフローエンジン Airflow をちょっと手元で動かしてみました。
■Airflow とは
Airflow についてサラッと概要を確認しておきましょう。
Airflow は元は Airbnb 社で始まったオープンソースプロジェクトで、2019 年には Apache Software Foundation のトップレベルプロジェクトとなりました。依存関係のある処理同士をつなぎこんだものを DAG (有向非巡回グラフ/Directed Acyclic Graph) として表現して、適切な順番で分散的に実行してくれるものです。
一連の機械学習実験タスクのような、お決まりの手順を自動化する上で役に立ちそうです。
Airflow は、 AWS や GCP 、Azure などの主要クラウドプラットフォームとも連携して使える、ということで、”エコシステム” としても発達している、「流行っている」と言えそうです。
なおこの記事は、2021年3月時点での最新版にあたる 2.0.1 に基づいて執筆されています。
■Airflow 事始め
ファーストステップは非常に簡単でした。「とにかく手元で起動する」だけなら、公式マニュアルに従って作業をすれば、スッと立ち上がります。
マニュアルに曰く「pip の最新版をつかうとローカルインストールは不安定だよ」とのことで、ローカルインストールは避けて、Docker 版を使いました。メッセージキューやデータベースも含めて、docker-compose で手間なく纏めて立ち上がるのは気持ちいいですね。
立ち上がった Web サーバにブラウザでアクセスして、デフォルトのユーザでログインすると、ダッシュボードにたくさんのサンプルが出てきました。
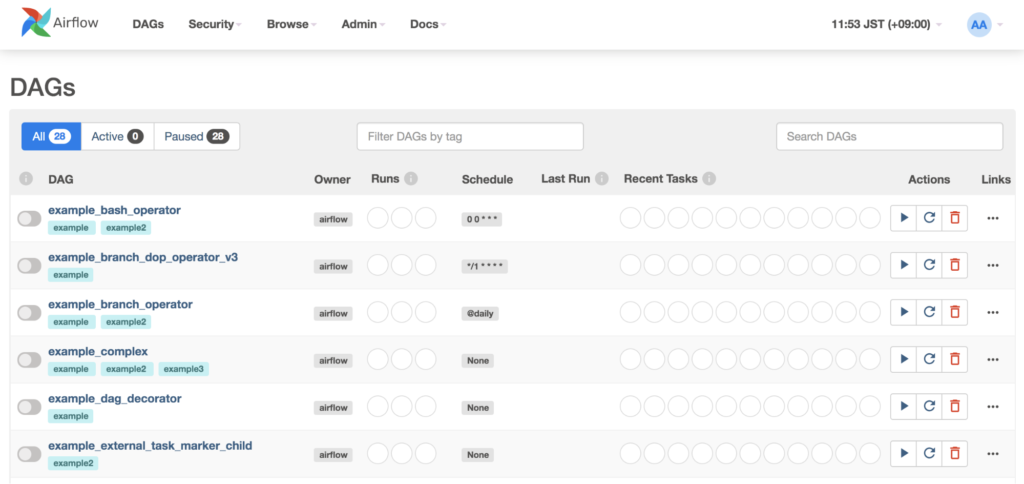
ひとつ覗いてみましょう。適当に、一番上にある「example_bash_operator」をクリックしてみます。
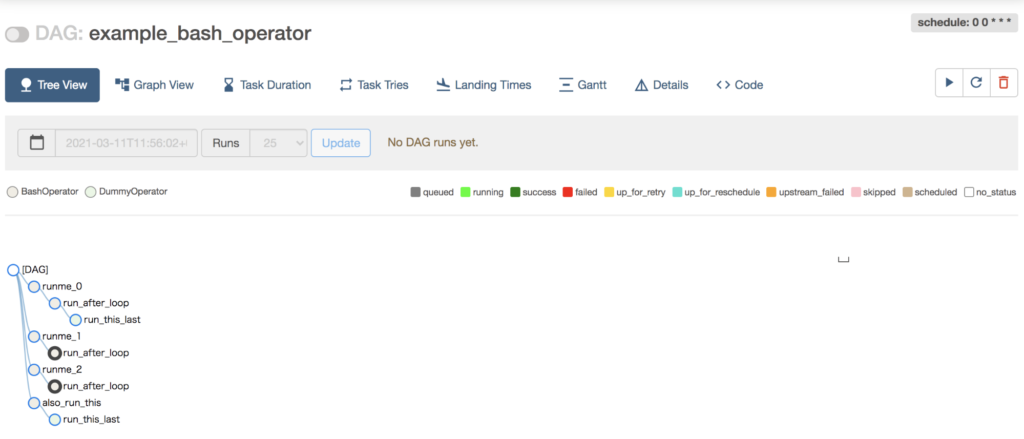
いくつかビューがあるようですね。DAG というくらいですから、Graph View を見れば雰囲気がつかめるでしょう。
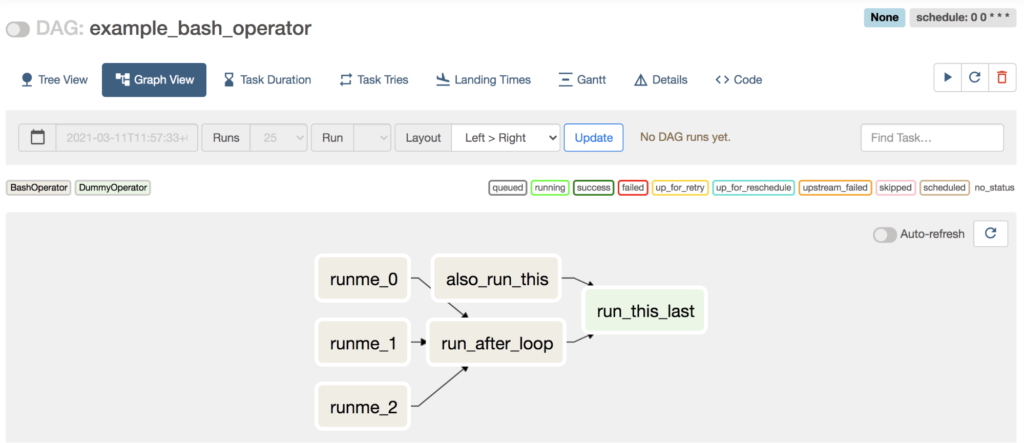
DAG 内のタスクの依存関係が図示されていますね。矢印の向きに沿ってタスクが実行される、ということでしょう。
Code ビューを見ると、この DAG を python のコードとして表現したものがでてきました。コードを読み解いてみると、この DAG では次の処理をするようです。
- runme_0 〜 runme_2: bash で `echo “{{ task_instance_key_str }}” && sleep 1` を実行する。
- run_after_loop: bash で `echo 1` を実行する。
- also_run_this: bash で `'echo "run_id={{ run_id }} | dag_run={{ dag_run }}"'`を実行する。
- run_this_last: なにもしない。
この二重ヒゲカッコで囲まれているものは、テンプレートエンジン(jinja)による「穴埋め」を受けるところです。Airflow が提供している名前(変数とマクロ)は https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html にリストされています。
ここで使われているテンプレートの変数は、それぞれ次の値に置き換わることになっています。
- task_instance_key_str: このタスクの実行を大まかに特定する文字列で、「どの DAG の、どのタスクを、いつ実行したものか?」が分かる内容になっている。
- run_id: 「DAG の実行/DAG Run」ごとの識別子。
- dag_run: DAG Run を表す、python 的なオブジェクト。
…...ということで、この DAG が何をしてくれそうか、ざっくり掴めました。
では、実行して、確かめてみましょう!
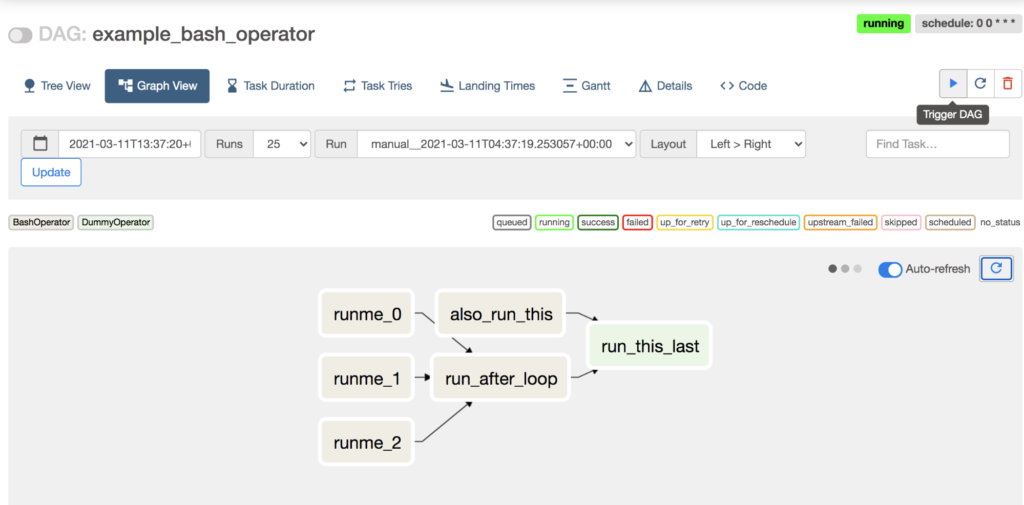
再生ボタンを押して Trigger してみましたが、右上に running と表示されたきり変化が見えません。
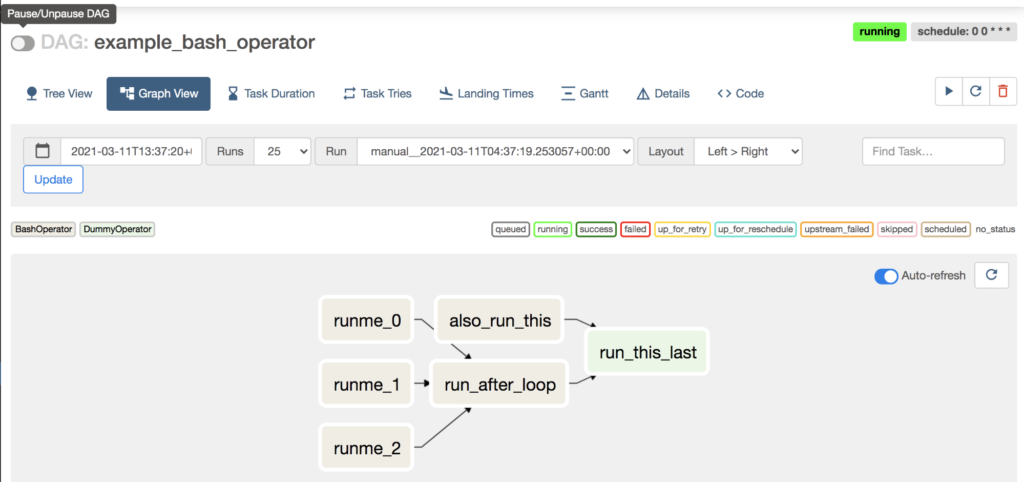
画面左上のトグルスイッチを動かして、このDAGを “unpause” します。
するとタスクの状態がどんどん進んでいって、DAG Run が success しました。
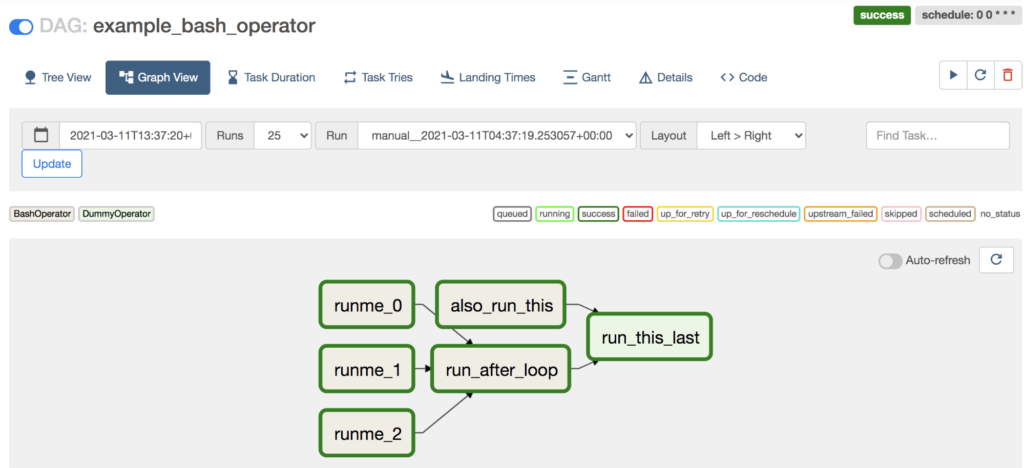
うまく動いたようです! 結果を見てましょう。
DAG のノードをクリックすると、このタスクについての操作メニューが出てきます。
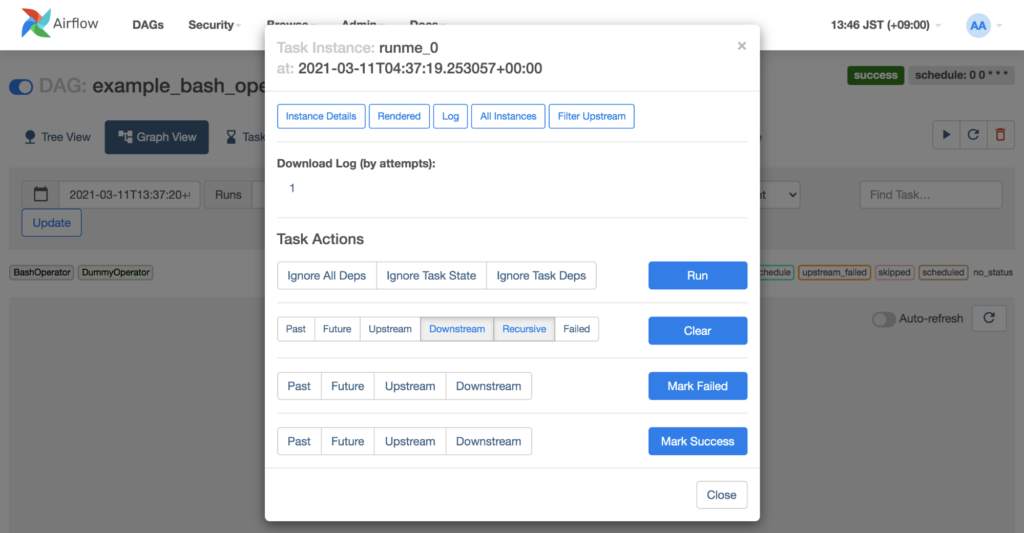
これはタスク runme_0 についてのものです。この上部の「Log」をクリックして、実行時ログを見てみましょう。このタスクからは、タスクの実行を大まかに特定する情報が書き出されるはずなのでした。
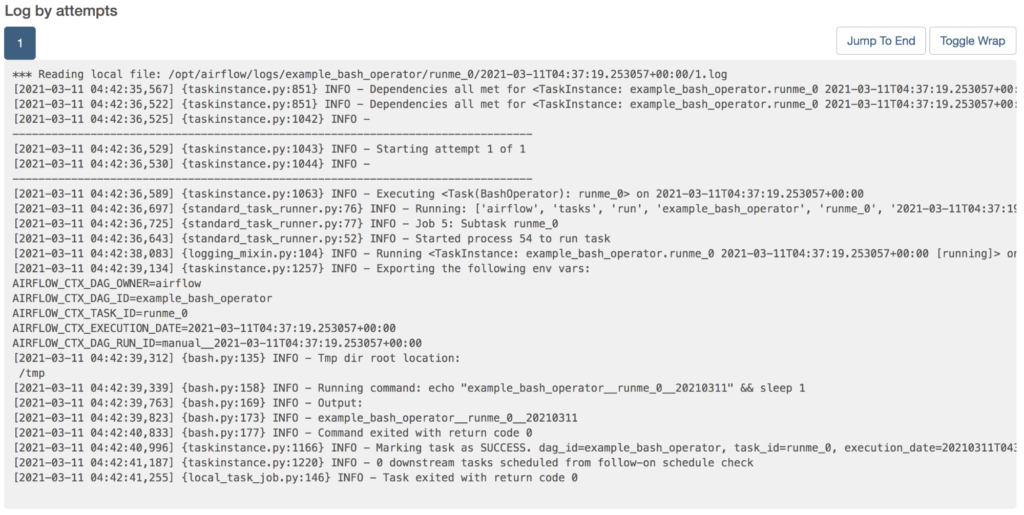
(ちょっとわかりにくいですが)ログ中の「INFO - Output:」とある行の次に、このタスクのコンソール出力があります。このタスクの実行を示す情報が、「DAGのID」と「タスクのID」と「実行日」がアンダースコアふたつで join されたもの、として書き出されていますね。
この実行の Gantt も見てみましょう。
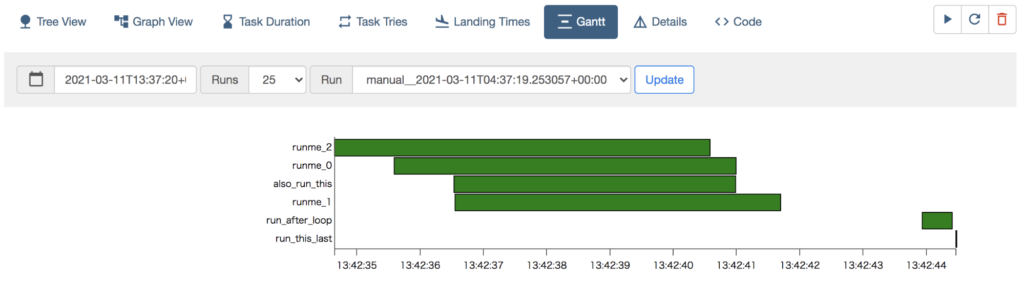
runme_0〜runme_2 と also_run_this が並走していて、全て終わってから run_after_loop、さらにその後に run_this_last が実行された、という記録となっています。DAG の順序が示すとおりです。
なるほどなるほど。よくわかりました。
マニュアルを見れば、Airflow にはこの BashOperator の他にも、 Python 関数を実行するオペレータや、Docker コンテナを実行するオペレータ、条件分岐するオペレータなど、いろんなオペレータが提供されており、さらにサードパーティのオペレータもたくさんあり、必要ならば自分でオペレータを定義してしまってもいいようです。
よしよし、なんとかなりそうな気がしてきました。あとはいい感じに DAG を書いて、適当な Operator をつなぎ込んでやれば、ワークフローをいい感じに管理できるってわけですね!
■Airflow Q & A
冷静になりましょう。「いい感じに管理できるってわけですね!」とは言ってみたものの、果たしてそうでしょうか?
いやいや、実際のユースケースに照らすと、考えておかないといけないことはまだたくさんありそうです。
Q1. DAG って、どうやって追加したらいいんですか?
サンプルはたくさんついてきましたが、自分の用途にあった DAG は自分でつくりたいものです。どうやって DAG を Airflow に追加したらいいんでしょう?
A1. “./dags” に置けばいい
チュートリアル https://airflow.apache.org/docs/apache-airflow/stable/tutorial.html#running-the-script にある通り、設定ファイル内で指定したフォルダに、DAG 定義ファイルを置けば良いです。この「DAG 定義ファイル」というのは「モジュール変数として `DAG` 型の値が公開されている python モジュール」のことです。
Docker 版では `docker-compose up` したディレクトリに作成した “dags” ディレクトリに DAG 定義ファイルを置けば、Airflow が認識してくれます。
さて、Airflow を一人で、ローカルでつかっているだけなら、なんでも好きにしたら良いです。ではチームで Airflow を使いたいときには、どうしたらいいんでしょう?
おそらくそれは、ユーザの工夫に委ねられています。
「NAS 上の適当な共有ディレクトリを dags に指定してやって、そこにめいめいDAG定義を置く」とか、「DAG も Git リポジトリで管理することにしておいて、CI ツールを噛ませて DAG 定義を自動デプロイする」とかいう工夫をすれば、複数人で使えそうです。
複数人でひとつの Airflow を使う場合、注意が必要なことがあります。それは「DAG の ID は、ファイル名ではなくて DAG 定義の内容に従って決まる」ということです。
試しに、複数のファイルに同じ ID の DAG を定義して Airflow に読ませてみたところ、ダッシュボードに出てくる DAG は一定しませんでした。
「DAG の命名規約を入れて、みんなで守る」という運用が必要になるでしょう。
Q2. ファイルの読み書きってどうなるんですか?
機械学習タスクのことを考えると、モデルを訓練して得たパラメータはしばしばファイルとして書き出されます。そうした「プログラム(タスク)が書き出したファイル」を、Airflow はどう扱うんでしょうか?
A2. Airflow はファイル書き出しを気にしない
タスクからファイルを書き出せば、ごく普通にファイルを書き出すことはできました。
ところで、Airflow はタスクを分散的に実行することもできるのでした。ということは、個々のタスクを実行する計算機は、他のタスクと同じなのか違うのか、予め知り得ないということです。ファイルシステムへのファイル書き出しはできますが、やらないほうがいいでしょう。ベストプラクティス集も、ローカルファイルシステムに書き出すのではなくて、外部ストレージ(Amazon S3 とか HDFS とか)に保存することを推奨していました。
DAG Run に関連付けて軽量のデータを Airflow に記録しておく仕組み(XCom)があるので、XCom にファイルの保存先(例; S3 のキー)を記録しておけば、過去の DAG Run が生成したファイルを、別の DAG Ran 内で取得して計算するタスクは作成できるでしょう。
ところで、そうやって外部に書き出したファイルは、単に普通のプログラムとして書き出しただけなので、開発者の手元のファイルシステムに取り寄せようと思うと、ちょっと面倒です。タスクは、実行時に「どこに何を置いたのか」というログを書き出すようにしておくべきでしょうね。
また、ある成果物を生成した DAG Ran が利用した入力値を生成した DAG Ran がどれか追跡する(lineage tracking)ことは、まだ容易ではないようです。
Q3. DAG を変更したらどうなりますか?
Airflow に登録してある DAG では、都合が悪くなったとしましょう。
たとえば「プロジェクトの途中で、モデルの評価指標を増やしたくなった」というケースです。
DAG を更新することは、可能なんでしょうか? やるとどうなるんでしょう?
A3. DAG も DAG Run も新しい定義を参照する
DAG 定義ファイルを変更すると、DAG の構造は、新しい定義のものに置き換わります。
そして UI 上は、DAG (や、以後新しく実行する DAG Run)だけではなく、過去の DAG Run も新しい定義の Graph に従って表示されます。ただし、新しく追加されたタスクは、当然実行されてないので、ログも、実行の成否も持ちません。
Airflow のベストプラクティス集( https://airflow.apache.org/docs/apache-airflow/stable/best-practices.html )には「DAG のタスクは決して削除してはいけません。タスクを削除したければ、代わりに新しく DAG を定義してください」といったことが書かれています。
DAG を上書きする運用は「記録を取りながら実験管理をする」という用途には向かないようです。DAG は更新しないで、ひたすら新規追加すべきでしょう。
ところで、「プロジェクトの途中で、モデルの評価指標を増やしたくなった」というケースに立ち戻ると、こうした場合には過去の実験についても再評価して検討したくなるものです。こうした要求にも、Airflow をうまく使うと応じることができそうです。
Airflow には「DAG のスケジューリング」という機能があり、定期的に DAG を実行してくれます。これが何をするかというと、DAG の有効期間のうちのスケジュールされた各時点について、DAG を実行してくれます。このとき DAG Run には「どの時点分の実行か」という情報が’(実時間とは別に)与えられます。
ですので、日時ベースでモデルが取得できる仕掛けになっていれば、「新しい評価基準を使う DAG」を新しく登録して unpause すると、あとはスケジュール機能が各モデルについて勝手に評価を進めてくれる、というわけです。これはちょっと便利そうです。
Q4. 「このタスクだけ GPU 機で」ってできますか?
機械学習系のワークフローにおいては、タスクによって使いたい計算機が異なる、ということはよくあります。
たとえば機械学習モデルを訓練するタスクでは、計算速度を稼ぐために GPU が利用されています。一方で「機械学習モデルの推論結果を元に、評価のための指標を計算する」ようなタスクでは普通の CPU で十分かもしれません。
GPU は貴重なので、必要なときにだけ使うことにしたいものです。タスクによって異なる計算機上で実行させる、ということはできるでしょうか?
A4. Kubernetes と連携することになりそう
マニュアルをサッと調べた限り、おそらく Kubernetes (以下、k8s)を利用することになるのでしょう。
Airflow のタスクとして k8s の Pod を実行できるものが存在します( https://airflow.apache.org/docs/apache-airflow-providers-cncf-kubernetes/stable/operators.html )。
これを利用すると、nodeSelector やアフィニティが指定できますから、「このタスクは GPU のある node で実行してくれ!」と要求できそうです。
KubernetesPodOperator に期待できることは、まだあります。タスクの実行が Pod 内に隔離されるなら、タスクを記述する言語や依存ライブラリを Airflow の実行環境と独立に選べるようになるでしょう。Airflow 環境自体のメンテナンスも簡単になると期待できます。
■まとめ
今日は、Airflow を使ってみたり、マニュアルを調べたりしたことを書き連ねてみました。
Airflow はそれなりに便利そうです。「お決まりのジョブを登録しておいて、定期的に実行したい」という要求には、バッチリフィットしているように見えます。たとえば、定期的に更新されるデータセットに対して、コンスタントに良好な性能を発揮できるか確認するタスクを自動化する、といった用途なら、そのものズバリ有用でしょう。
一方で、実験管理的な文脈でうまいこと運用するにはちょっと工夫が要りそうだな、という感触を得ています。たとえば......
- いくつか、運用上の約束事をつくって、周知する必要がある
- 外部ストレージの選定と、キーの付け方の規則
- DAG 設定ファイルの登録運用の規則
- DAG ID の決定の規則
- Airflow を運用するには、他にも必要なものがある
- k8s クラスタ
- プライベートな Docker Image Repository
- 上述の外部ストレージ
- DAG / DAG Run と、その関連データをうまく関連付けて記録するにはどうしたらいいだろう?
- 過去の DAG Run の出力を再利用する時、「どの DAG Run を再利用したか」という情報はどうやればスマートに残せる?
- 「ある DAG Run に依存している DAG Run のリスト」は得られるか?
- 実験条件やログを読み取るのに、個々の DAG Run / タスクを調べなきゃいけないのは結構手間がかかりそう。楽にならないか?
- 自分が関心を持っている DAG Run を見つけるには、どうしららいい?
- 自分が実行したのと同じ DAG で、他のチームメンバーがまた別に DAG Run している可能性がある。
- Airflow のダッシュボード上、同じ DAG の DAG Run 同士はタイムスタンプ程度でしか識別しないようだ。
などなど、懸案事項はポロポロ出てきます。ユーザ側で決めるしかない問題もありますが、DAG やストレージ運用の設計に関わるものもあり、「現実的にうまくいく方法」を見つけるには、使い込んでみる必要がありそうです。
とはいえ、このあたりのことは「ワークフローエンジンを使うこと」それ自体に伴う複雑さであるようにも思われます。Airflow に限らず、新しい道具をつかうときは大抵そうですが、これまでの面倒くささから逃れられる反面、新しい複雑さを引き受けることになるものです。
Airflow 、流行っているだけあって、なるほどとても興味深いツールです。今後は自分でつかってみて、上手い使い方を研究してみます。
プロフィール
著者:髙岡陽太
株式会社オープンストリーム/技術創発推進室
長らく Web 系のシステム開発をしてきたが、2019年頃から機械学習関連の案件に携わり始めた。
ディープラーニングモデルの開発からその API 化、フロントエンド開発まで、必要とあらば一通り手掛ける。
最近は、機械学習それ自体はもとより、機械学習開発を支える技術としての MLOps に興味を持っている。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps