Keep Innovating! Blog

論文紹介:スマホ上でも超高速に顔認識ができるAI技術 "Attention Mesh"
目次
- ■はじめに
- 1. 顔の形状の推定
- 1.1. 基本的な用語
- 1.2. 顔の形状推定の例
- 2. Attention Mesh
- 2.1. Model architecture
- 2.1.1. 注視機構
- 3. 顔の検出
- 4. 実験結果
- 4.1. 推論速度
- 4.2. 推論精度
- 5. アプリケーションへの応用
- 6. なぜAttention Meshは高精度で軽いのかまとめ
- 6.1. 精度
- 6.2. 速度
- 6.3. 考察
- 7. さいごに
- 8. 関連する研究
- 8.1 A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection
- 8.2. Spatial Transformer Networks
- 8.3. BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
- 8.4. Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs
- 8.5. How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
■はじめに
みなさんはじめまして、この春から技術創発推進室に異動となりました松村です。私は機械学習のなかでも画像認識全般に興味があり、昨年に画像処理エンジニア検定エキスパートを、今年の3月にJDLAのE資格を取得しました。まだまだ駆け出しですが、社会の課題解決に向けて、最新技術やビジネス動向のキャッチアップなど、日々精進していきたいと思います。
みなさんはGoogle MediaPipeというものをご存知でしょうか。MediaPipeとは、Google社が提供するライブストリーミングのためのオープンソースのMLソリューションです。このMediaPipeを利用すると高性能なAI画像処理アルゴリズムを利用したARアプリケーション等を簡単に作成できます。また、クロスプラットフォーム対応となっており、主要なOS上で実装が可能です。
MediaPipeで提供されている機能の中に、顔の形状推定を行うFace Meshというものがあります。このFace MeshはAttention Meshという技術を利用してモバイル・デバイス上でも高速かつ高精度な人の顔の位置と表情の推論を可能にしています。
https://google.github.io/mediapipe/solutions/face_mesh

(本家サイトより引用)
下記URLのページからブラウザでデモが試せます。顔の動きに追随して、顔の形状を検出しているのがわかります。見るだけでも面白いのでぜひ試してみてください。
https://developers-jp.googleblog.com/2020/04/mediapipe-tensorflowjs.html
今回は、Face Meshがどのようにして高速・高精度な推論を可能にしているのか、ということをAttetion Meshの論文(Grishchenko, Ivan, et al. "Attention Mesh: High-fidelity Face Mesh Prediction in Real-time." arXiv preprint arXiv:2006.10962 (2020).https://arxiv.org/abs/2006.10962 )から見ていきたいと思います。
1. 顔の形状の推定
本題に入る前に、顔の形状を推定するタスクがどうやって行われているのか、ということについて少し触れておきたいと思います。顔の形状の推定とは、2次元の画像データから3次元の形状(顔のランドマークの配置)を推定するというもので、フェイス・アライメントやフェイス・レジストレーションとも呼ばれています。
1.1. 基本的な用語
顔の形状推定に登場する用語について押さえておきたいと思います。
(1) メッシュ
メッシュというのは数式で表された曲面ではなく、図2[8.4])のように多数のポリゴン(多角形)の集合で構成された曲面です。メッシュは複雑な曲面形状を設計する場合に大変有効な手法で、この3Dメッシュの頂点の座標を推定することにより、顔の形状を推定することができます。
(2) ランドマーク
ランドマークとは顔のパーツや輪郭を決めるキーポイントのことで、ここではメッシュ上の特定の頂点だと思っておけばよいでしょう。このメッシュやランドマークをどうつくるか、ということも、研究によって異なっています。

1.2. 顔の形状推定の例
(1) Face Alignment Network (FAN)
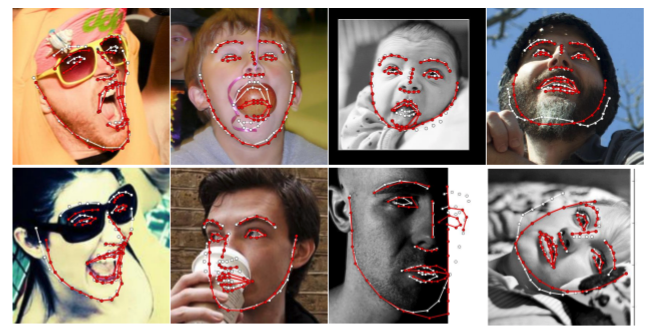
では、ここからが本題です。顔の形状推定の例をみてみましょう。図3はFace Alignment Network(FAN)という先行研究[8.5]からの引用です。顔の特徴を決める上で重要になる箇所に予測したランドマーク(図中の白い点が予測の位置、赤い点が正解の位置です)があるのが見てとれると思います。この例では68個のランドマークを検出しています。
2. Attention Mesh
顔の形状推定がどのようなものか少しわかったところで、Attention Meshについて見ていきたいと思います。Attention Meshは3Dメッシュの頂点を独立したランドマークとみなし、その位置をニューラルネットワークで直接推定します。
Attention Mesh が採用したメッシュには、精度向上のために、人間の顔の中でも変化が大きく、重要性が高いと予想される領域(両眼や口)に、より高い密度でランドマークが割り当てられています。そのため、眼や口の輪郭を高精度に予測することが可能です。ランドマークの数そのものも多く、実に 468 点にも登ります。この数は、前述の FANに比べると 7 倍です。そして、Attention Meshのさらにすごいところは、これだけランドマークを増やしてもなお、モバイル・デバイス上でのリアルタイムな推論を可能にしているという点です。
さて、Attention Mesh は従来よりもたくさんのランドマークを推定をしているにもかかわらず、なぜ高速に推論できるのでしょうか? その答えはこのモデルのアーキテクチャにあります。
それでは、モデルアーキテクチャを見ていきましょう。
2.1. Model architecture
Attention Meshは、256✕256画素の顔を含む画像を入力として受け取り、顔のランドマークを予測して出力します。この入力画像には顔以外のものが含まれていないことが前提なので、図4に示すように、あらかじめ顔検出器等で顔の領域だけを抽出した画像を入力します。なお、図4の背景がグレーになっている部分がAttention Mesh です。
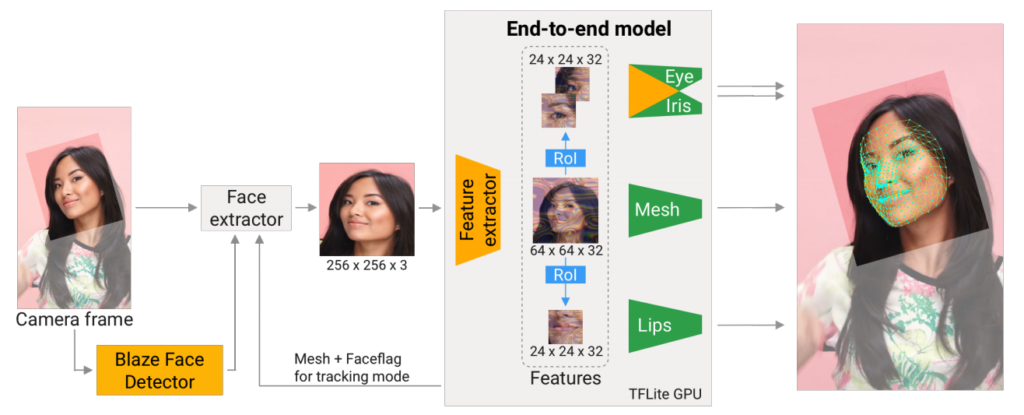
Attention Meshはいくつかのサブモデルから構成されています。
- 顔全体のランドマークを予測し、重要な領域(=眼や口)の境界線を切り出すサブモデル
- 眼の領域に特化してランドマークを予測するサブモデル
- 口の領域に特化してランドマークを予想するサブモデル
推論時の処理の流れは、およそ次のとおりです。
- 256x256画素の入力画像を特徴抽出機に通して、64x64個の特徴マップを得ます。
- それを1つめのサブモデルに通して顔全体の478個のランドマークを3Dで予測します。さらに、重要な領域(両眼と口)に相当する境界線(bounds)を抽出します。
- 眼と口の専用サブモデルはそれぞれ、注視機構によって絞り込まれた 24x24個の特徴マップから、各領域のランドマークを予測します。
2.1.1. 注視機構
眼や口のサブモデルには、眼や口の部分だけを切り出した特徴マップを入力します。この切り出す役目を担うのが、「注視機構(Attention mechanism)」です。
Attention Mesh では、注視機構として spatial transformer module[8.2] というものを利用しています。これはアフィン変換を用いた画像(ここでは特徴マップ)の切り出し機構です。ここでは 64x64 の特徴マップから 24x24 の領域を切り出しています。
アフィン変換は微分可能な関数として表現できるので、勾配法を用いる学習モデルの中に組み込むことができます。ただし、本論文では機械学習でアフィン変換を求めているかどうかは明記されていません。
この処理の流れの中に、Attention Mesh が高精度かつ高速になる重要なポイントが隠されています。
(1) ランドマーク予測の精度のポイント・ 重要なパーツに特化したサブモデル顔全体のメッシュを予測するモデルの他に、両眼と口に特化したサブモデルが導入されています。図4. の「Eye」「Iris」、「Lips」と書いてある部分がそれです。サブモデルは独立しているので、必要に応じてそれぞれ別個のチューニングができるという利点があります。実際、本モデルにおいても、眼と口に専用の正規化処理(後述)を加えることで予測精度を改善しています。 ・ 注視機構眼や口に特化したモデルには、眼や口の部分だけを切り出したデータを入力したいものです。このパーツを切り出す役目を担うのが、「注視機構」です。
この研究では、注視機構として spatial transformer module というものを利用しています。これは、画像の中の欲しい部分に「うまくズームインする」ような、空間的な変換(spatial transformation。正体はアフィン変換)を与えるものです。 ・ 顔のパーツの正規化予測の精度をさらに高めるために、眼と唇が水平に整列し、サイズが均一になるように正規化を行なっています。眼や口は表情によって様々な形状になります。このように変換しておくことにより、顔の局所的な変化に対応しています。 ・ 眼と虹彩を別々に出力眼に特化したサブモデルにおいては、虹彩(いわゆる黒目)部分が6x6画素以上のサイズならばそれを眼の輪郭とは別のデータとして出力します。眼の特徴量を上手く再利用して、あまり動かない眼のランドマークとは独立に、よく動く虹彩のランドマークを取り出せるようにしています。虹彩を独立して出力することにより虹彩、つまり視線の動きまでも捉えることができます。
(2) ランドマーク予測の速度のポイント・ エンドツーエンドなネットワーク従来の顔形状認識ネットワークでは、「カスケード」アプローチが用いられていました。これは、いくつか顔形状予測モデルに画像や特徴を順次入力して、最終的に高精度な出力を得ようというものです。ところがこれは、データがAI = GPU に出たり入ったりするので、時間効率の悪いものでした。
これに対して Attention Mesh では、顔の位置が特定できれば、あとはひとつの AI の中だけで計算が一通り終わるようになっています。このことが速度向上につながっています。 ・ 計算リソースの集中注視機構により、計算リソースを顔の中でも重要なパーツ(両眼と口)に集中投入することによりパフォーマンスの低下を防いでいます。
下図5のようにサブモデルによって眼や口の形状がほぼ正確に検出されていることがわかります。

3. 顔の検出
顔の検出については、Attention Meshの範囲外となるので余談となりますが、顔の検出結果は、顔の形状推定の精度に関して重要なポイントでもあるので触れておきたいと思います。
まず、Attention Meshに入力する顔の画像はBlaze Face Detector[8.3]によって検出しています。
ここで、注目したいのが図4のFace extractorから出力されてAttention Meshに入力されている顔の画像です。Blaze Face Detectorによって検出された元の顔画像と比較して、眼や唇が水平に、顔が中心になるように回転され、さらにスケールが正規化されています。
顔のランドマーク検出アルゴリズムは、顔の検出器によって提供される画像に依存しているという問題があり、テスト時とトレーニング時で異なる矩形の画像が提供されると検出器の性能が大きく低下してしまいます。しかし、実際にモバイルカメラからなどのリアルタイム入力を考えた場合、顔の大きさや向きは様々な状態になることが予想されます。
そこで、検出した顔の画像を正規化してからAttention Meshへ連携することにより、顔の検出結果に依らず顔の形状推定がロバストになります。先行研究[8.1]でも議論されているように、リアルタイムに入力される様々な顔画像データに対して、一定の精度の担保が可能ということになります。
4. 実験結果
では、実際のパフォーマンス及び精度を見てみましょう。比較対象として、カスケードモデル(ベースメッシュ、眼、唇の各領域ごとに独立して訓練したモデルを連続して実行するもの)を使っています。計測には モバイル・デバイスとしてPixel 2XLを用いTFLite GPU推論エンジン利用しています。
4.1. 推論速度
まず、処理速度について見てみましょう。Attention Meshのパフォーマンスは、普通に手に入るモバイルデバイス上で、カスケードモデルと比較して25%以上高速に動作する結果となっています。加えて、著者たちは、Attention Mesh は GPU ワンパスで計算が終わるため、カスケード版に比べて更に 5% 速くなると主張しています。

4.2. 推論精度
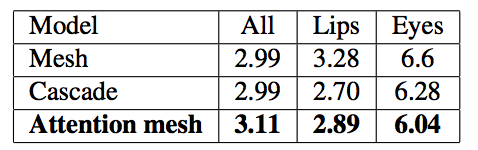
次に、予測精度を見てみます。指標としては、キーポイントの予測位置とGround Truthの位置との平均距離が採用されています。つまり、値は小さいほど正確だ、ということです。この距離は、画像ごとのスケールの違いに影響されないように3次元の眼間距離(唇と眼の場合はコーナー間の距離)で正規化しています。Attention Meshとカスケードモデルを比較した結果、眼の領域ではカスケードモデルよりも優れた性能を示し、唇の領域では同等の性能となっています。
5. アプリケーションへの応用
最後に、アプリケーションへの応用の一例としてAR Makeupへの応用例を見てみましょう。顔のメッシュを正確に予測することは、AR Makeupのようなアプリケーションでは非常に重要になります(メイクは1mmでもズレていたら致命的ですね)。下図に左側のように、検出にわずかな誤差があるとレンダリング効果が不自然になってしまいます。対して、右側のAttention Meshでは唇の正確な形状の検出が可能なため、より自然な印象になっています。

6. なぜAttention Meshは高精度で軽いのかまとめ
ここまで、Attention Meshについ見てきましたが、高速かつ高精度につながりそうなポイントがいくつかありました。速度の面と精度の面でそれぞれポイントをまとめてみたいと思います。
6.1. 精度
- 眼や口など顔の重要なパーツのランドマーク密度を高くすることにより、複雑な形状の予測に対応している。
- 注視機構の導入により顔のパーツ別での推論処理を実現している。これにより、形状が複雑でランドマーク密度が高い眼や口の領域についても高精度な予測を可能にしている。
- 動きの少ない目のランドマークからよく動く虹彩を独立して出力することにより、虹彩の動きを捉えることを可能にしている。
- 顔のパーツを正規化することで、予測の精度をさらに高めている。
6.2. 速度
- エンドツーエンドなネットワークによる推論により、モバイル・デバイスにおいては大変コストのかかるGPUとCPUの間のやりとりを削減している。
- 注視機構により、計算リソースを顔の中でも重要なパーツ(両眼と口)に集中投入することでパフォーマンスの低下を防いでいる。
6.3. 考察
論文内では言及されていない点について考察してみたいと思います。精度及び速度の改善において、spatial transformer moduleの導入は重要なポイントになっているのではないでしょうか。
spatial transformer moduleによって顔や顔のパーツを正規化しておくことにより、各サブモデルが対応する必要がある入力の多様さを低減しています。(様々な形状やサイズの物を予測するより同じような形状やサイズであるものを予測する方が簡単そうです。モデルのサイズも小さくて済みそうです。)
結果として、サブモデルに要求される処理能力を抑えることができ、推論が容易になっている可能性があります。推論が簡単になるということは、モデルの精度と高速化に寄与しているのではないかと思いました。
以上のような工夫により、推論の精度を犠牲にすることなくモバイル・デバイス上での推論処理の軽量・高速化を可能にしているのではないでしょうか。
7. さいごに
今回ご紹介したAttention Mesh論文を読んで感銘を受けたことは、顔検出を具体的アプリケーションとして成立させる、という目的意識が論文全体にはっきり貫かれている点です。いろいろな先行研究の成果を集大成して統合し、目的とする機能・性能を実現していくストーリーは大変素晴らしいと思いました。
私もAIの研究開発からアプリケーションにつなげていく仕事に関わっています。研究開発の過程では、さまざまな細かな問題が必ず発生します。ついつい、その細かい問題に深入りして、本来の目的を見失いそうになることがあります。この論文のように、目的を常に明確に意識して仕事を進めていくことが重要だな、と改めて痛感しました。
以上となります。最後までお付き合いいただきありがとうございました。
8. 関連する研究
8.1 A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection
https://openaccess.thecvf.com/content_cvpr_2017/papers/Lv_A_Deep_Regression_CVPR_2017_paper.pdf
8.2. Spatial Transformer Networks
https://arxiv.org/abs/1506.02025
NNアーキテクチャに組み込むことで、空間変換機能(アフィン変換)を提供するSpatial Transformer Moduleを提案しています。既存のCNNアーキテクチャに組み込むことにより、画像の中で最も関連性の高い領域を選択(注視)し、かつそれらの領域を期待されるポーズに変換することで、後続のレイヤーでの推論を容易にすることが可能です。また、Spatial Transformerを組み込んだモデルはエンド・ツー・エンドで学習することができます。
8.3. BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
https://arxiv.org/abs/1907.05047
Attention Meshの前身となると思われる論文です。
8.4. Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs
https://arxiv.org/abs/1907.06724
Attention Meshの前身となると思われる論文です。
8.5. How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
https://arxiv.org/abs/1703.07332
プロフィール
著者:松村久美子
株式会社オープンストリーム/技術創発推進室
ITエンジニア歴長めで組込から基幹システムまで経験は広範囲。趣味の投資に機械学習を利用したいと思い独学で勉強開始。
現在は画像認識全般に関心あり。JDLA Deep Learning for ENGINEER 2021#1、CG-ARTS 画像処理エンジニア検定エキスパート保有。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps