Keep Innovating! Blog

AI開発のベストプラクティス...... だけじゃない!アンチパターンもお忘れなく
目次
- 1. この論文について
- 2. この記事では
- 3. 設計と開発/Design & Development のアンチパターン
- 3.1. データリーク/Data Leakage
- 3.2. こっそりハイパラ調整/Tuning-under-the-Carpet
- 4. 性能測定/Performance Evaluation に関するアンチパターン
- 4.1. 早合点病/'PEST'
- 4.2. 恩人違い/Bad Credit Assignment
- 4.3. 自己採点/Grade-your-own-Exam
- 5. 運用/Deployment & Mentenance に関するアンチパターン
- 5.1. デプロイしてそれきり/'Act Now, Reflect Never'
- 5.2. 訓練してそれきり/Set & Forget
- 5.3. 悩ましいコミュニケーション/'Communitcate with Ambivalence'
- 5.4. サービスとしてのデータ危機/'Data Crisis as a Service'
- 6. おわりに
みなさんこんにちは! いかがお過ごしでしょうか。
成功してますか。失敗してますか。五分五分でしょうか。ぼちぼちうまくいっている、ということはあれど、一点の曇りなく成功! というのは、......どうでしょう? 私も一度はそういう状態になってみたいものです。
さて今日は、今年の7月末に発表された論文「Using AntiPatterns to avoid MLOps Mistakes」( https://arxiv.org/abs/2107.00079 )から、機械学習タスクのアンチパターン、つまり、失敗しやすいポイントをご紹介します。
「ああ、あるある、やったわコレ」というものもあれば、「気をつけてはいなかったが、たしかにマズイな」というものもあり、なかなか面白いんですよこれ。
1. この論文について
この論文は、著者らが機械学習パイプラインを開発した中で気がついた「教訓/lessons」をまとめたものです。
著者らは、ニューヨークメロン銀行(The Bank of New York Mellon)で金融系の分析をするシステムの開発とデプロイにあたって様々な問題に出くわしたのだそうです。そこから教師あり学習・予測問題に関連する「アンチパターン」、すなわち「やってはいけない設計・運用に、名前をつけたもの」をまとめて、列挙しています。
論文中の表には、このように、
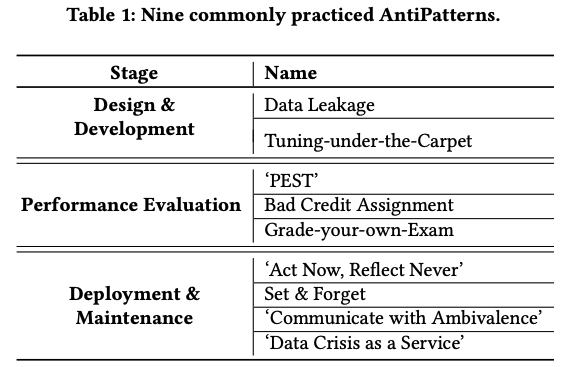
アンチパターンが、発生箇所によって大分類されていて、それぞれに具体的なアンチパターンがいくつか挙げてある、という形に整理されています。
2. この記事では
この記事では、これらアンチパターンについて順番に見ていくことにします。
また、せっかくなので、それぞれのアンチパターンに、日本語で名前を付けてみました。アンチパターンたるもの、その名を呼べなければいけませんからね。
先程あげた表と同様の形で示せば、こうなります。(番号は、本記事の章番号)
| 発生箇所 | 名前 |
| 3. 設計と開発 | 3.1. データリーク 3.2. こっそりハイパラ調整 |
| 4. 性能測定 | 4.1. 早合点病 4.2. 恩人違い 4.3. 自己採点 |
| 5. 運用 | 5.1. デプロイしてそれきり 5.2. 訓練してそれきり 5.3. 悩ましいコミュニケーション 5.4. サービスとしてのデータ危機 |
さあ、一緒に苦い果実を噛りましょう!
3. 設計と開発/Design & Development のアンチパターン
3.1. データリーク/Data Leakage
「データリーク」という言い回しは、もしかすると聞いたことがある、という方もいらっしゃるんじゃないでしょうか。「訓練時に使うデータと、テスト時に使うデータは分離すべきだが、その分離に失敗している」という種類のものです。
テストデータの情報(の一部)を訓練に使ってしまえば、テストでは過剰に良い性能がでて、一方で実地での性能は思わしくない、といった傾向がでるでしょう。
発生理由や、リークの起き方に応じて、いくつかのサブパターンに分類されています。
3.1.1. いないいないばあ/Peek-a-Boo
データが生じたタイミングと収集されたタイミングの間に時間差があることがあります。
たとえば、月末締めの月報ベースでのデータ収集をするのだとしましょう。すると、データが発生したあと収集されるのはいつかといえば、当然月末まで待って収集されることになりますね。
この時間差を考慮しないでモデリングしてしまい、意図せず異なる時点の情報を混ぜ込んだまま分析や訓練に使う、というアンチパターンがこれです。
予測問題においては、予測したい時点以降の情報が混ざっていれば、リークになってしまいますね。上記の例で言えば、月初時点での予測モデルを作るときに、月末まで含めたデータで訓練してしまう、といったケースです。
3.1.2. オーバーサンプリングによるリーク/Oversampling Leakage
理想的には、クラス分類モデルの訓練には、全クラスがバランス良く含まれたデータセットを使いたいものですが、いつもそううまくいくわけではありません。クラス分布が大きく偏った(アンバランスな)データセットしかない場合に、少数派のクラスをオーバーサンプリングして水増しすることでバランスをとる、という対処をすることがあります。
このときに問題になるのが、オーバーサンプリングをするのと、データセットからデータをランダムに選んで訓練用・テスト用に分割するのと、どちらを先にやるのか? ということです。ここで「オーバーサンプリングしてから、データセットを分割する」と、このアンチパターンに当たります。
そういうことをするとどうなるかというと、少数派クラスについて複製されたデータが、訓練セットにもテストセットにも含まれる、という可能性が出てしまうんですね。これはデータが漏れています。
正しい手順は「データセットを分割してから、それぞれオーバーサンプリングする」です。こうすれば、訓練用とテスト用との間で重複したデータが生まれません。
3.1.3. 外部のメトリクスによるリーク/Metrics-from-Beyond Leakage
たとえば、画像を前処理するにあたって標準化することを考えてみましょう。
つまり、各画像から、平均値を引き、標準偏差で割るわけですが、もしこのとき、訓練データ用のものもテストデータ用のものも、一緒くたにして求めた平均と分散に基づいて標準化すると、ちょっとまずいことになります。訓練にテストデータを含む統計情報を使ってしまっているからです。
このように、不適切な前処理を経由して"ハイパラを漏らしてしまう"というのがこのアンチパターンです。
3.2. こっそりハイパラ調整/Tuning-under-the-Carpet
訓練時にハイパーパラメータを記録しない、というアンチパターンがこれです。これは私も何度かやってしまいました。
著者らは「再現可能にし、適用を用意にするために、ハイパーパラメータを、はっきりと・骨身を惜しまず記録すべきだ」と書いています。
最近は AutoML なんかでハイパラ探索も自動化されたりしているようですが、そうした場合も個々の訓練について、具体的にどのハイパラが割り当てられたか、は記録されてないとマズいですね。
4. 性能測定/Performance Evaluation に関するアンチパターン
4.1. 早合点病/'PEST'
‘PEST’ とは、中世にヨーロッパで流行った病のことでも、政治・経済・社会・技術の頭字語( https://ja.wikipedia.org/wiki/PEST%E5%88%86%E6%9E%90 )でもなく、この論文では
the reported empirical gains are actually just an occurrence of the Perceived Empirical SuperioriTy (PEST) antipattern.
のこと。意訳すれば「一回はうまくいったしいいだろ、論文にしちゃえ」といったところでしょうか。
科学的成果というものは、実証を繰り返すことで信頼が置けるものになるものです。が、ML分野では実証が不足している、と著者らは言っています。
機械学習分野では、論文にされた成果でも再現性が怪しい、再現性の危機だなんていう話もありましたね( https://www.nature.com/articles/d41586-019-03895-5 )。これはその種のアンチパターンといえるでしょう。
著者らはこのアンチパターンに関して、対策としてでしょう、次の事を勧めています。
- モデル同士の比較や評価をするときには、常に同一の実験パイプラインを使うこと
- KISS原則( https://ja.wikipedia.org/wiki/KISS%E3%81%AE%E5%8E%9F%E5%89%87 )に従って、まずはシンプルなモデルから始めて、網羅的な比較ができるようになってから、特殊な構造をモデルに取り込むこと
4.2. 恩人違い/Bad Credit Assignment
新しいアーキテクチャなどを導入して性能が改善したとき、その性能改善の原因を誤って判断する、というアンチパターンがこれです。
新しいアーキテクチャを導入するなら、ablation study をして、新しい部分が性能に寄与した量をちゃんと測る必要があるでしょう。施した工夫がいくつかあるとき、工夫をひとつだけ省いたものとも性能を比較してはじめて、個々の工夫のどれが・どのくらい効いているのかわかる、というわけです。
このためには、比較対象となるベースライン条件のモデルについても、実験条件のモデルと比較できるように訓練しておく必要があります。
そしてもし ablation study ができないなら、その新しいモデルの挙動についての洞察を深めるために、そのアーキテクチャの変な挙動や安定性についても調査すべきだ、と著者らは主張しています。
4.3. 自己採点/Grade-your-own-Exam
このアンチパターンは「モデル開発を続けていると、試みている手法にはまり込んでしまって、他の手法を試さなくなってしまう」というものです。
研究チームが最初になにか着想を得て、それを試してみるところまでは良いのですが、そのあと他の人々の評価にさらされないままになっていると起きてしまう、とありました。
また論文では、同じテストセットを繰り返し使うことで、「結果を見てから仮説を立てる」(Hypothesizing After Results are Known; HARK) ということをしてしまい、暗黙的なデータリークになる、という問題も指摘されていました。
こうした問題を避けるには、最終的なテストセットを評価用セットとは別に作って、最終的な性能評価のときにだけ使うようにすることが勧められていました。
この問題に対する対応というものは、本質的にはガバナンスの問題であって、第三者による監査ができるようにするために、モデル開発とは独立に Ground Truth を管理して、モデルを評価したなら「いつ、どのデータをつかって」評価したのか、記録をとっていく必要がある、と述べられていました。
5. 運用/Deployment & Mentenance に関するアンチパターン
5.1. デプロイしてそれきり/'Act Now, Reflect Never'
デプロイしてそれっきりにしてしまい、モデルを更新しない、というアンチパターンです。
(後述しますが)コンセプトドリフトや、かんたんにケアできそうな見落とし、adversarial attack などがある場合でも、モデルの様子を見ることも、調整することもなく放置してしまうと、そうした問題を見過ごしてしまいます。
実地のモデルの挙動を追跡したり、デバッグしたりできるようにしておいて、信用が置けるか判断する「メタモデル」が必要であり、また、LIME ( https://arxiv.org/abs/1602.04938 ) のようなモデルの判断理由を分析するツールなどが有用かもしれない、と述べられていました。
5.2. 訓練してそれきり/Set & Forget
機械学習システムは、データ同士が、同じ分布から独立にとられたものであること(独立同分布/Independent and Identically Distributed; i.i.d)を仮定しています。
しかしながら、現実はしばしばその仮定に反します。見つけたい現象に対応するデータ分布が、時が経つにつれて変わるということがあるのです。これがコンセプトドリフト、と呼ばれる現象です。
こうしたコンセプトドリフトには、監視して検出したり、モデルを新しいデータを使いながら調整したりすることで対応してゆく必要があります。
こういうわけで、「訓練してそれきり」はアンチパターンだということなのです。
5.3. 悩ましいコミュニケーション/'Communitcate with Ambivalence'
モデルに予測をさせる、ということはよく行われています。一方で、モデルのもつ不確かさの情報がユーザに示されていないと、ユーザや下流のシステムはモデルの予測をどう取り扱っていいかわかりません。
著者らは「不確かさについての情報を示すことは、大規模なデプロイメントにおいては最優先のタスクだ」とまで言っています。
5.4. サービスとしてのデータ危機/'Data Crisis as a Service'
オリジナルのデータを加工して訓練データなどをつくるとき、その加工の経歴を残しておかないと、あとからデータ加工が再現できなくなってしまって困ります。こうなると、データをどうやって加工したものか再発見する必要が生じてしまいます。これはマズいパターンですね。
著者らによると、機微情報を扱う場合に、データ提供元の組織が、機微な部分をマスクしてくるような場合などが典型的で、こうした加工がモデル設計者にとって秘密裏に行われてしまうと、「サービスとしてのデータ危機」が起きるということです。
データの系統情報の記録(リネージ/lineage)を取って、「なにを、どうした結果、どういうデータを得たか」という情報を芋づる式に辿れるようにする必要があります。これは、データ操作が多段階に及ぶなら、出力のほかに、中間的なものについても把握すべきです。
著者らによると、この実現にはグラフデータベースが有用であったということです。
6. おわりに
論文になる話というと、普通は「成功した!SotA!Novel archetecture!」みたいな華々しい話のことを考えてしまいがちです。翻って、こういう「うまく行かなかった時の話」というのは貴重ですよね。
今回ご紹介した内容は、とても私には身につまされる話でした。「ああ、そこにアンチパターンがあるなんて考えなかったよな」というものがチラホラありました。特に「悩ましいコミュニケーション」のパターンって、まだ気にしたことがなかったような...... ううむ。
機械学習モデルをラボから出すのは、それはそれで1つの難しいタスクであることが(再)確認できました。次は、もっとうまくやりましょうね。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps