Keep Innovating! Blog

最先端のMLOpsを知りたければ、テスラ社の AI DAY を見逃すわけにはいきません
目次
みなさんこんにちは。技術創発推進室の松村です。
テスラ社(https://www.tesla.com )は、電気自動車で有名な企業ですが、実はAI技術でも世界トップクラスの企業であることをご存知でしょうか? 自動運転の実現のために必要な高度なAI機能を実現すべく、理論研究やソフトウェアの開発だけでなく、専用の車載用AIハードウェアや、研究開発用のGPUスーパーコンピュータのハードウェアを自社開発するほどテスラ社はAIに「本気」です。
今まで、噂などで断片的に伝わっていたテスラ社のAI技術ですが、ついに彼ら自身の言葉で紹介される機会が訪れました。それが 2021年8月19日に開催されたTesla AI Day(https://youtu.be/j0z4FweCy4M)です。
ここではTeslaの自動運転システムであるAuto Pilot、AI学習用のコンピュータdojo、そしてteslabotの開発状況などについて発表されました。この中から、今回はAuto Pilotにフォーカスして内容を紹介したいと思います。
私たちオープンストリームは、最近 MLOps に特に注目していますが、この Auto Pilot の仕組みは、MLOpsの実装としてみても最先端であることが分かります。この点にも着目してお読みいただければさらに面白いと思います。
1. Auto Pilot 概要
TeslaのAuto Pilotは、車両に設置された8台のカメラから周辺の情報を処理した結果を元に車の運行計画を立てた後、車両に制御コマンドを出力することにより自動運転を実現しています。カメラから入力される情報はTesla Visionによって処理され、運行計画の立案と決定はPlannerが担っています。
Tesla AI Dayでは、これらのTesla VisionやPlannerに加えて、Auto Pilotを学習させるための大規模データセットを自動で作成するAuto Labeling、Simulation機能について解説されています。
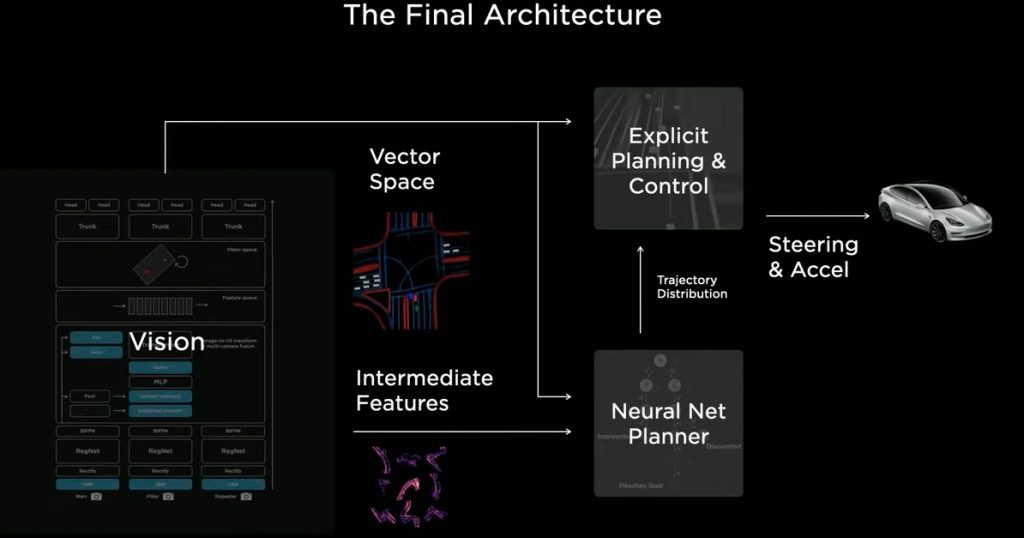
2. Tesla Vision
Tesla Visionの役割は、車両の周囲に設置された8台のカメラから送られてくる画像をニューラルネットでリアルタイムに処理して運転に必要な情報(車線、縁石、交通標識、信号機、車の位置、向き、奥行き、速度などの3次元的な位置)を3次元ベクトル空間で表現することです。自動運転では、画像空間上の予測値を利用して直接車を操作することはできないので、3次元ベクトル空間での予測値を得る必要があります。

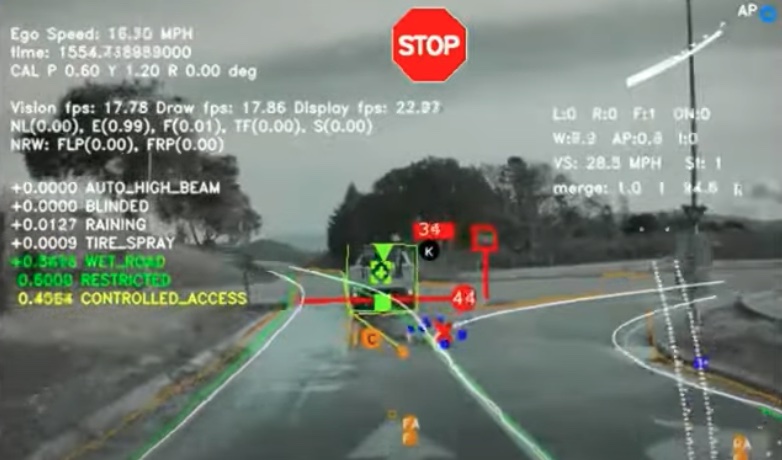
およそ4年前の段階では、8台のカメラから入力される画像を個別にニューラルネットに入力し処理を行っていました。
この写真は、個々の画像別に処理をして予測を行った結果の例です。動画では一時停止の標識の認識や、一時停止線、車、信号、ゴミ箱、コーンなどの様々なものが検出されている様子がわかります。
しかし、FSD(Full Self Drive)に向けてはこれでは十分ではありません。自動運転で必要なのは、3次元ベクトル空間での予測値ですが、画像空間で得た予測値をベクトル空間へ投影すると良い結果が得られないことがわかりました。これは、画像空間からベクトル空間へ正しく投影するためには、ピクセルごとに非常に正確な深度が必要となるためです。
2.1. Multi Camera Network
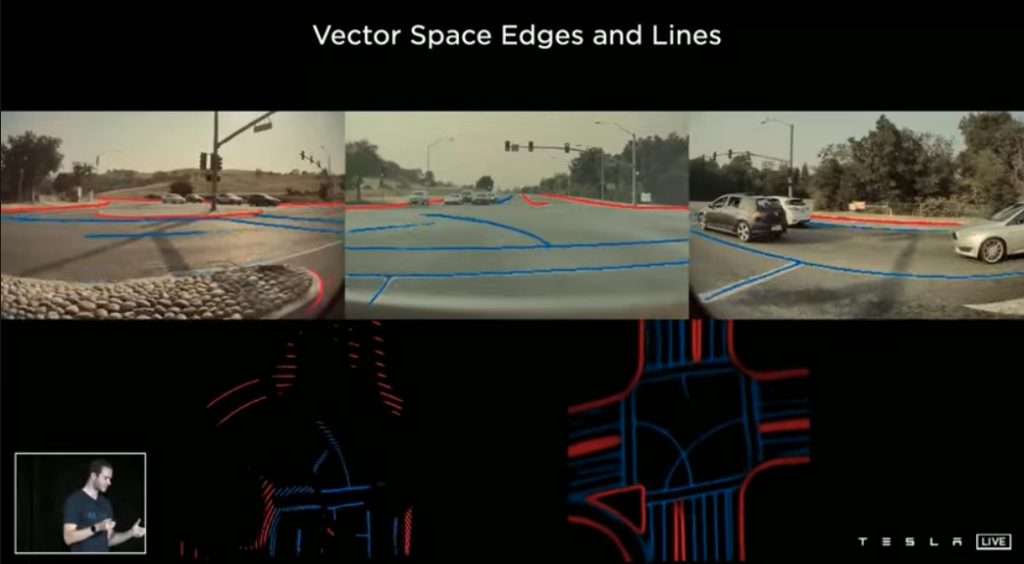
そこで、画像空間で予測を行うのではなく、3次元ベクトル空間で直接予測を行うことにしました。8台のカメラから送られてくる画像を同時に1つのニューラル・ネットワークに入力するとベクトル空間上の特徴が直接出力されるようなネットワークをTransformerを利用して実現しています。
この写真は、Multi Camera Networkによりベクトル空間で予測した結果です。画像空間からベクトル空間に投影したもの(下段左)と比較して、Multi Camera Networkによりベクトル空間で直接予測(下段右)したものは大変良好な結果になっています。また、これにより、物体検出についても多くが改善されました。
しかし、このモデルでは時間方向についての考慮がされていないのでまだ不十分です。ここで得られる予測は時間に関して完全に独立しています。
また、ニューラルネットからベクトル空間の予測を得たいなら、ベクトル空間のラベルが必要になります。この点ついてはこのあとAuto Labelingのパートで紹介されています。
2.2. Feature Que and Video Module
自動車を安全に運行するためには、様々な情報をを一定時間記憶しておく必要があります。そこで、ニューラルネットから得られた特徴をキャッシュするFeature Queと、それらの情報を融合するためのSpatial RNNを用いたVideo Moduleを導入しました。
Feature Queにはキネマティクス(車がどのように動いているかを示す速度と加速度)も入力されるため、カメラから見ているものを追跡するだけでなく、車がどのように移動したかも追跡しています。また、このキューには時間経過だけでなく車の移動距離に応じても情報がキャッシュされます。これにより、少し先に信号があることや、50メートル手前で道路標識を認識することや、検知した車が停止しているのか、動いているのか、速度はどれくらいかなどを判断することが可能になります。
この動画では車が交差点で信号待ちをしているケースを示しています。車が目の前を横切ると一時的に前方の車が遮られてしまいますが、Feature QueとVideo Moduleの導入により一時的に物体が遮蔽されたとしても、車が存在していることを記憶しているため見失うことがありません。
3. Planner
Plannerの役割は、Tesla Visionから得たベクトル空間上の情報を利用して、車の安全性、快適性、効率性を最大限に高めながら車を目的地まで運ぶことです。
例えば、車線変更を行う場合、1.5msという非常に短い時間に様々な操作を2500回も検索します。そして、検索した候補から、最適な条件に基づいて最終的な運行計画を決定します。
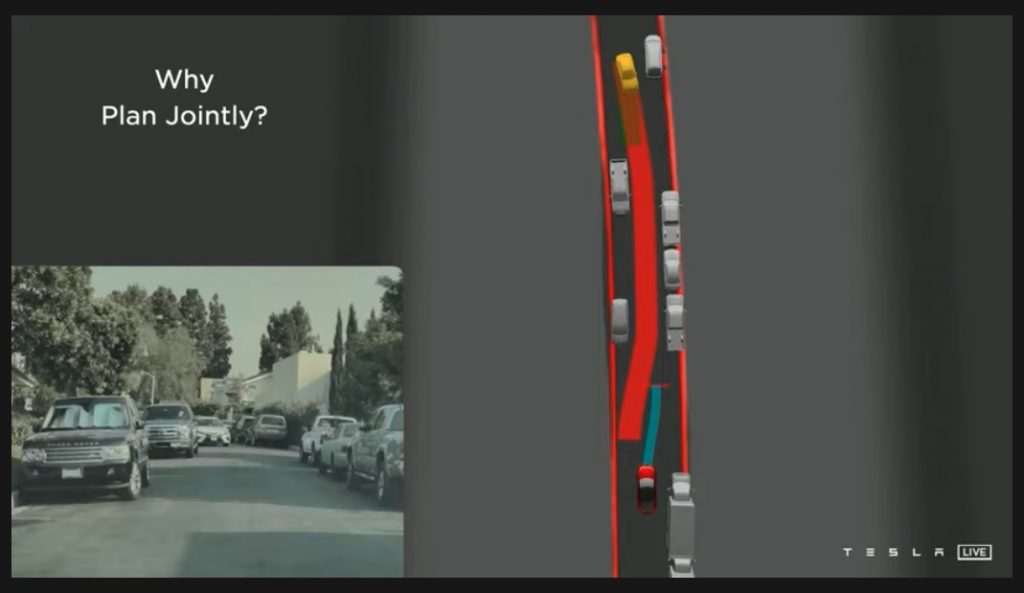
また、安全な運転のためには、周囲の車と自分の車の関係性を把握しながら運転する必要があります。Plannerは自分だけでなく周囲に存在するすべての車の運行計画を立てた上で、シーン全体の交通の流れを最適化しています。
車両が1台しか通れない狭い道路を通行するケースでは、対向から向かってくる車が見えると、自動運転車は自分が進むべきか、または相手に譲るべきかを自分の周囲のスペースや対向車の速度や対向車の周囲のスペースなどから判断します。こういった場面では、以前のAuto Pilotでは相手に譲るという消極的な選択をしがちでしたが、今では臨機応変な対応が可能になっています。
4. Labeling
これまでのラベリングは2次元の画像に写っている物体に対して、「これはコーンだ」、「これは車だ」といったアノテート作業を画像1枚1枚に対して行っていました。しかし、前述したように、必要なのはベクトル空間上のラベルなので2次元の個々の画像にラベリングするのではなく、3次元または4次元空間でのラベリングを行うことにしました。
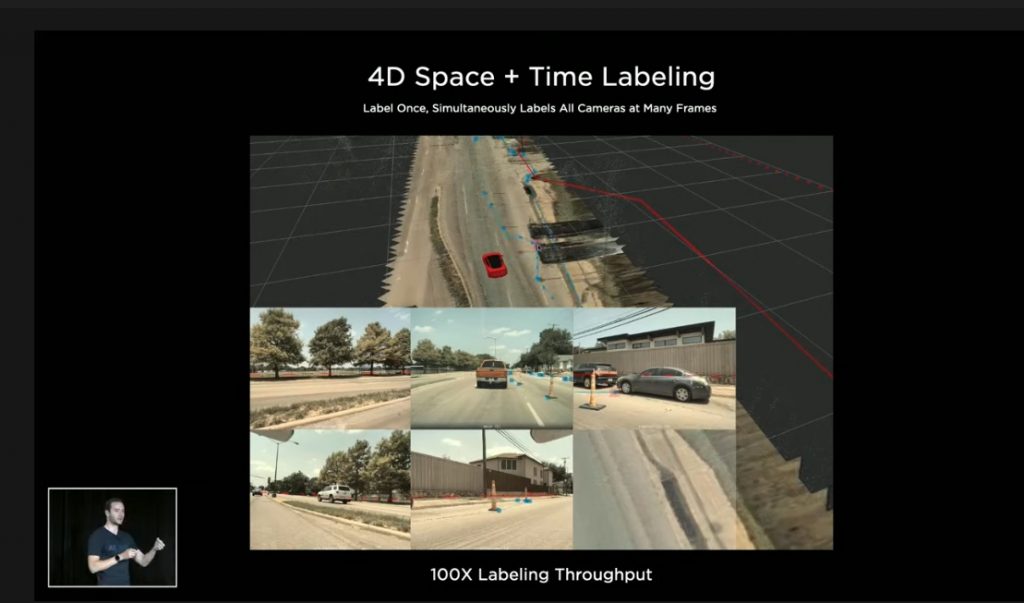
4.1. 4D Space + Time Labeling
この画像は、ベクトル空間で直接ラベルを作成し、その変化をカメラ画像に再投影している様子です。上部のベクトル空間上でラベルを変更すると下部のカメラ画像上のラベルが連動して動いています。これによりラベリング作業のスルー・プットが向上しました。
4.2. Auto Labeling
さらに、より早く大規模なデータセットを作成するためのAuto Labeling Pipelineがあります。走行しているテスラ車(テスラ社エンジニアや顧客が運転している車)から収集したクリップ(動画やIMUデータ、GPSやオドメトリなどの高密度なセンサーデータを含むエンティティ)をサーバに送り、多くのニューラルネットワークを実行してセグメンテーション、深度ポイントマッチングなどの中間結果を生成します。その後、多くのアルゴリズムを経て、ネットワークのトレーニングに使用できる最終的なラベルセットを生成します。

NeRF(https://arxiv.org/abs/2003.08934 )の技術を利用して、3Dの静的な障害物を任意に再構築し、ラベリングすることもできます。

また、過去と未来の双方のトラッキング情報を参照して、関連付けながらラベリングできます。たとえば、道路の反対側にいる歩行者が一時的に前を通る車によって遮蔽されてたとしても、歩行者の存在を認識しておく、といったことが可能です。運行計画を立てる際には、たとえ人物が一時的に隠蔽されていても、その存在を認識し、考慮する必要があるため、Plannerにとって非常に重要なことです。
この画像では、左側の緑の車の背後にいるオレンジの人の存在を確認することができることを示しています。
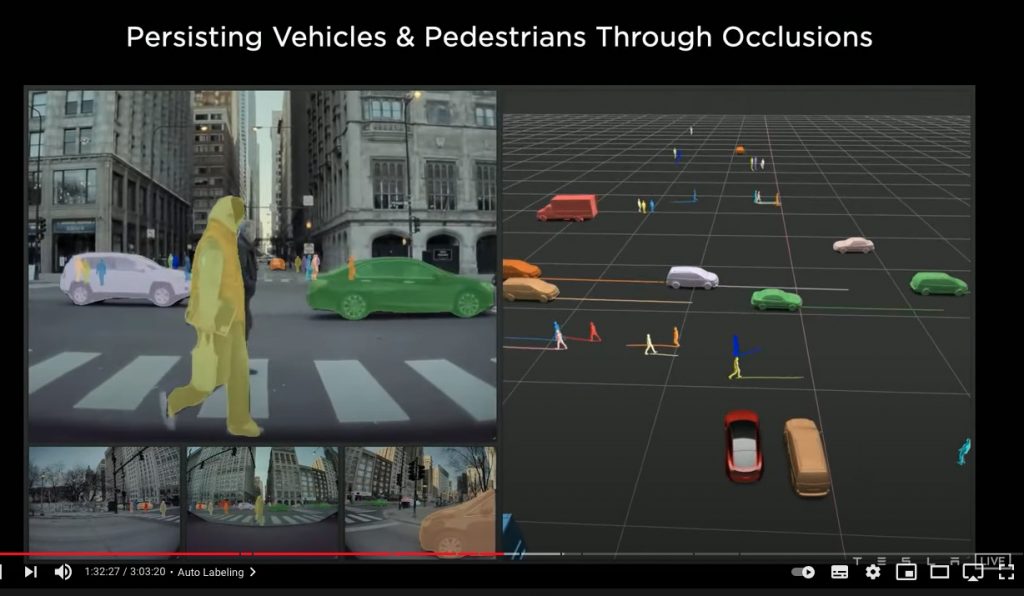
静止している物体、動いている物体のすべてにアノテーションを施し、オクルージョンがあった場合でもラベルをつけることが可能です。

5. Simulation
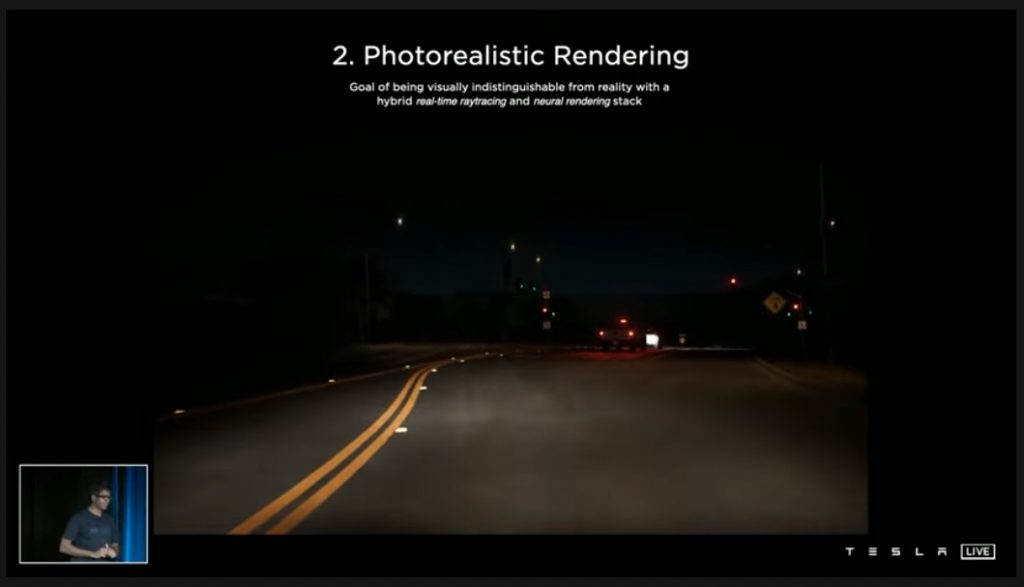
現実では起こりにくい状況やラベリングが難しい場面などは、Simulationを利用して検証することができます。シミュレーションのシナリオはアルゴリズムを使ってプログラム上の手続きとして自動的に作成することができます。これにより大規模なデータセットを素早く作成、シミュレーションすることが可能です。また、このシナリオデータは、アルゴリズムですべての状況や事象を作り出しているので、画像空間でもベクトル空間でも、完璧なラベルを与えることができます。

Simulationでは単にきれいな画像を作るのではなく、車の中で見ているのと同じような景色を作成する必要があります。そのため、カメラの多くの特性をモデル化し、特殊なアンチエイリアシングやニューラル・レンダリングを利用し、レイ・トレーシングによるライティングなどによって、とてもリアルな画像を作成することを可能としていいます。
さらに実際に走行しているTesla車に障害が発生した場合など、特殊な状況であってもそれと同じ状況下におけるシミュレーションを可能にすることができます。すなわち、車から収集した実際のデータをAuto Labeling Pipelineに通して、シーンの3D再構成とすべての移動物体を生成し、これに元の視覚情報を組み合わせることで、同じシーンを合成できます。そのようなシミュレーション・シナリオを作成することで、起こった障害をSimulationを利用して検証することが可能になります。

6. 学習・評価・デプロイ
Teslaでは巨大なニューラルネットワークとシミュレーション・エンジンを、数千台のGPUと2万台弱のCPUを使って構築し、独自のデバッグツールを利用して1週間に100万回以上の評価を3,000台以上のFSDコンピュータを対象に行っています。
①走行しているテスラ車からクリップ・データを収集、②Auto Labeling Pipelineを通してデータセットを作成、③モデルを学習、④モデルを評価、⑤テスラ車へアップロードする流れになっており、①〜⑤の流れがループしています。このようにMLOpsを実践し見事に機能しています。
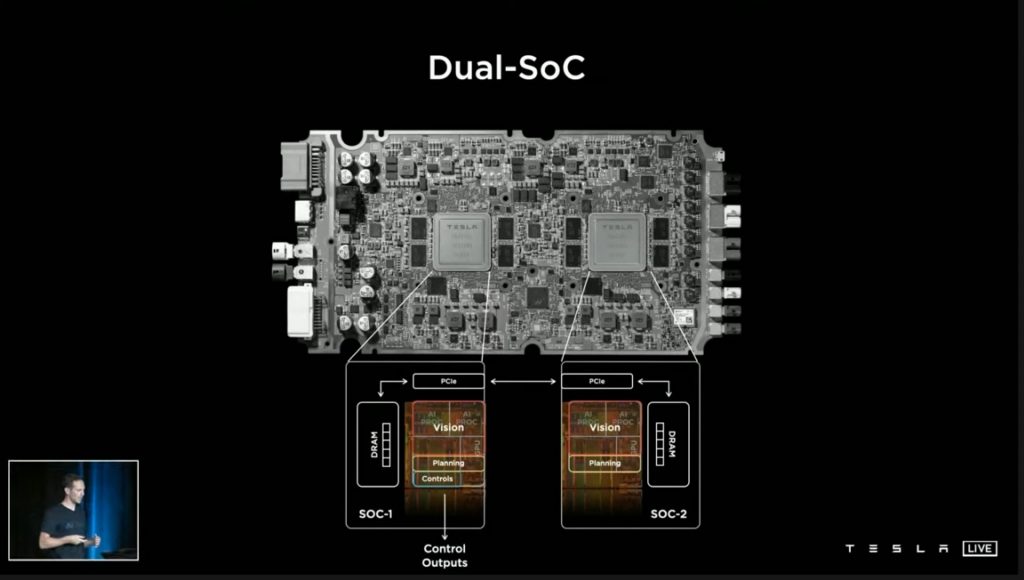
車に搭載されるFSDコンピュータには2つのAIエンジンがありますが、常に片側のAIエンジンだけが車両に制御コマンドを出力しています。もう一方のAIエンジンは、計算能力の拡張用ですが、この2つはハード・ソフトともに共通仕様で、入れ替え可能なものとなっています。
ニューラルネットワークの開発を反復的に行うのを支援するデバッグ・ツール。同じニューラルネットワークモデルの異なるリビジョンからの出力を、ビデオクリップを通して何度でも比較することができます。
7. さいごに
イベントの冒頭でイーロン・マスク氏は、テスラは単なる電気自動車会社ではなく、現実世界に適用可能なAI技術に関してのリード・カンパニーであるといった趣旨のことを言っています。Tesla Visionだけも、物体検知、セグメンテーション、3D再構築などあらゆるAI・CV技術が総動員されているだけでなく、製品に搭載したAIモデルを日々進化・洗練させていくための仕組みが MLOps 基盤とワークフローとして確立されておりイーロン・マスク氏の言う通りだなと思いました。
最近のAI技術は、モデルの精度を追求するだけではなく、実システムでの運用を目指すフェーズに入っていると感じます。現実の問題に対して課題を適切に設定し、その課題解決のための有効なAI技術を選択、システムへ落とし込む能力が非常に重要になってきていると思いました。
本記事では簡単な紹介に留まりましたが、Tesla AI DAYでは技術的な点が細かく解説されており、大変興味深い内容になっています。興味のある方は是非観てみてください。
今回は以上となります、ここまで読んでいただきありがとうございました。
著者プロフィール
名前:松村久美子
株式会社オープンストリーム/技術創発推進室
ITエンジニア歴長めで組込から基幹システムまで経験は広範囲。趣味の投資に機械学習を利用したいと思い独学で勉強開始。現在は画像認識全般に関心あり。JDLA Deep Learning for ENGINEER 2021#1、CG-ARTS 画像処理エンジニア検定エキスパート保有。
- テレワーク
- リリースノート
- リネージ管理
- knitfab
- OpeN.lab
- ChatGPT
- 画像生成
- 画像認識
- 書籍紹介
- 対話
- 自然言語処理
- Open Innovation
- アカデミック
- 活動報告
- ビジネス
- ガジェット
- オープンイノベーション
- TIPS
- 線型代数
- 数学
- Airflow
- 論文紹介
- MediaPipe
- 顔認識
- 可視化
- 異常検知
- プラモデル
- イノベーション
- 自動運転
- AI
- MLOps